

The term “precision medicine” is relatively new and was mainly highlighted after 2011 thanks to a report by the U.S. national research council, which focused on the need for a new classification of diseases1. In fact, it is a so far successful attempt to rename the much older term “personalized medicine”, which refers to the research effort to create and adopt therapies that take into account the unique characteristics of each individual. These characteristics referred to, and continue to refer to, primarily genes and, to a lesser extent, lifestyle, environment, and other factors. As we will see later, “precision medicine” does not involve creating a different drug for each individual, “made to order”. Primarily, the term describes the tools and processes used to classify patients into a population subcategory using combined criteria (e.g., smokers who simultaneously carry a specific genetic variation). The “precision” and “personalization” here concern the way in which prognosis and treatment will be determined each time, that is, the way medicine is practiced.
The renewed interest in personalized medicine is attributed to the former US president, Obama. Regarding health policies, Obama became more widely known in our parts for his reforms concerning insurance. Even more so, since the “Affordable Care Act” – also known as Obamacare – was ultimately repealed by the Republican administration on May 4th of last year, a development expected to lead to millions of uninsured in the US in the coming years. However, beyond being able to project a face of “social sensitivity,” Obama also had another significant advantage as a “showcase” of the American administration. He is a “star” in terms of stage presence and argumentation, even when presenting or discussing advanced techno-scientific issues. On January 20, 2015, in his annual “State of the Union Address” before the joint session of the House of Representatives and the Senate, he announced the “Precision Medicine Initiative” as a project that would lead medicine into a new era. Ten days later, on January 30th, in the East Room of the White House, he explained in his relevant speech on the topic, facing a large number of scientists and entrepreneurs who applauded him:
[…]
There is something called precision medicine – in some cases it is also called personalized medicine – which gives us one of the greatest opportunities for new medical revolutions that we have never seen before. Doctors have always recognized that each patient is unique, and doctors have always tried to tailor their treatments as best as possible to each individual. It is possible to match a blood transfusion with the blood group. This was a great discovery. How would you feel, if a cancer treatment could be matched with our genetic code as easily as a standard procedure? How would you feel, if determining the correct dosage of a drug was as simple as taking a temperature?This is the promise of medical precision – delivering the right treatment, at the right time, to the right person. Eight out of ten people with a type of leukemia saw their platelet count return to normal with a new drug targeting a specific gene. Genetic testing for HIV patients helps doctors determine who can benefit from a new drug and who will experience harmful side effects.
And technological advances mean that we are still at the beginning. The year that Dr. Collins helped extract the human genome sequence, it cost about 100 million dollars, and today it costs less than 2 thousand. Wearable electronics make it easier than ever to record vital signs, from blood sugar to heartbeats. Electronic medical records allow doctors and researchers to collaborate more closely than ever before. And the most powerful computers allow us to analyze data faster than ever before.
Therefore, if we combine all these emerging technologies, if we focus on them and ensure that the connections will be made, then the probability of discovering new therapies, the probability of applying medical methods more efficiently and more effectively so that success rates are higher, so that there is less waste in the system, which in turn means more resources to help more people – the possibilities are unlimited. So, now is the time to unleash a new wave of developments in this field, in precision medicine, as we did with genetics 25 years ago.
And the really good news – which shows that this is the right moment – is that there is bipartisan support for the idea – (laughter) – here in Washington. […]
It is not the first time that Obama has dealt with such issues. As he himself mentions later in his speech, from 2005 to 2007 he worked as a senator, in collaboration with Republican Richard Burr, to promote the same concept, advancing a bill titled “Genomics and Personalized Medicine Act”.
The “Precision Medicine Initiative” may be considered a project of the previous US administration, but in reality, projects of this kind and scale can only concern broader directions of “innovation” and technological change taking place in medicine as well. And as is the case in such situations, promises and expectations are great, while the profits of corresponding companies grow as their achievements penetrate ever deeper under patients’ skin – and not only.
the promise and the data
Although the term “precision medicine” is new, personalized medicine has been for years an “unfulfilled promise” of medical sciences. A promise that starts from choosing the appropriate and most effective treatment and preventing diseases and ends in developing new innovative drugs and therapies that will “work wonders”.
As in our days, the “accuracy” of therapy – the choice of a correct one – focuses on the correct diagnosis of the disease. The criteria for such a diagnosis in the current example of the practice of medicine often arise from some initial clinical examination. However, even more so, the diagnosis and the choice of treatment and the corresponding drugs are determined by the results of laboratory tests. The limits of values that, in combination with other factors (age, weight, gender, etc.), determine the treatment arise as a range around the average of the values corresponding to the “healthy” condition. However, it is not uncommon for the determination of these limits to change, let alone from the moment pharmaceutical companies and diagnostic centers have their reasons to exert such pressures.
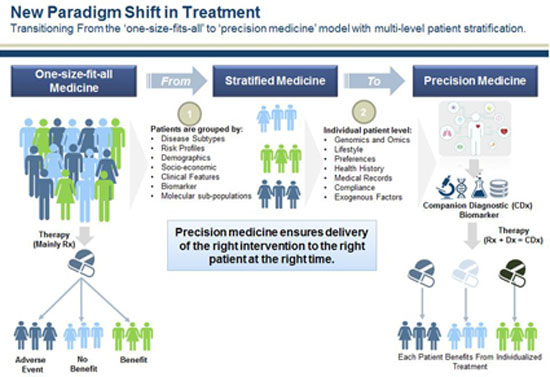
The concept of “precision” no longer refers only to providing treatment for a specific disease, but mainly to the specific individual to whom it is applied. The effectiveness problem that specialists identify in “standard”-average patient treatments seeks its solution in the collection of personal data and their analysis.
The Precision Medicine Initiative (PMI) plan was funded for 2016 with 215 million dollars. 130 million were allocated to the National Institutes of Health (NIH) organization with the goal of collecting diverse medical data from a cohort of one million or more American volunteers on a common platform, so that this data can be analyzed in combination. The data that will be provided by the volunteers include their medical records, genetic profiles, chemical measurement test profiles, microorganisms inside and on the body (microbiome), data related to the environment and lifestyle, data produced and provided by the patient himself, personal device and sensor data (e.g. smartphones, wearables) etc.
It is not the first time that the large-scale collection of medical data has been attempted2. Besides the Department of Health, the US Department of Defense and the Department of Veterans Affairs are actively involved in implementing the PMI program. The latter has already, since 2011, launched the “Million Veteran Program” (MVP) for collecting genetic data. By 2016, MVP had collected the genome data of 500,000 volunteer American veterans in its database. Similar programs have begun to be implemented in other countries as well, while globally there are 95 different genetic databases, more or less specialized, recorded3 which are controlled by companies, universities, research programs, consortia, or governmental organizations.
The difference of the PMI program lies mainly in the fact that it aims to merge a large piece of the whole of modern technological trends. Next-generation DNA sequencing technologies and molecular measurements, the ubiquitous portable and wearable devices that detect the effects of the environment, lifestyle and daily behavior on the body, the development and implementation of electronic health records in hospitals and health centers, the data recorded by insurance companies, as well as a multitude of research centers constitute the “raw material” for the promise of improving therapies and producing new drugs that, with the correct dosage, will target the “precise”-personal cause of the disease, as deeply as possible within the cells.
Beyond the laboratories of geneticists, pharmaceutical companies and their experiments with new drugs, which attempt to push into the market while bypassing any restrictions of drug marketing regulations, “technological developments” now clearly also concern the necessary informational infrastructure of the large databases that are created from the collection of health data. And all evidence suggests that this health (mega-)data constitutes a potentially rich goldmine for those who will take care in a timely manner to create a form of usable accumulation of it.
The largest volume of these big data to be accumulated concerns the analyses of whole genome sequencing (wgs) that will be attempted. The approximately 6 billion base pairs that constitute the human genome of somatic cells would require only ~1.5 gigabytes (1.5×109 bytes, equivalent to 2 CDs) for their storage. However, to correct the errors that occur during recording, each base is “read” multiple times in order to perform a “local alignment” with a “reference genome.” The actual volume of uncompressed data collected per genome is several times larger (~80-140 gigabytes). When including at least one backup copy maintained for security reasons, the data volume corresponds to at least 200 gigabytes for each individual. Storage needs for the genome of 1 million individuals, who will constitute the PMI volunteer cohort, correspond to at least 200 petabytes (200×1015 bytes)4. If, combining all recording technologies, the data volume is expected to reach astronomical levels, something similar applies to the computational power that must be deployed, as well as to the data analysis algorithms expected to be applied.
Among the dozens of universities, institutes, research centers and hospitals participating in the implementation of the PMI’s volunteer program, a key role is played by the biotechnology subsidiary of Alphabet (note: Google’s parent company), Verily Life Sciences. In collaboration with Vanderbilt University and the Broad Institute of Cambridge University, Verily has taken a central role in organizing the “Data and Research Support Center,” which deals with the collection, organization and analysis of data that will be provided to researchers. And as expected, the data will end up in Google’s Cloud infrastructure, while the company’s big-data analysis algorithms will be used to analyze them. A quick look at the price list of ‘Google Cloud Platform’5 shows that the cost of storing a human wgs (~100 GB) is $25 per year. Undoubtedly, the promise of personalized medicine, aside from enormous data sizes, also includes astronomical (or perhaps genomic!) profits!
Similar trends appear to exist in the market for bio-banks and laboratory machines that produce human DNA sequencing. The company Illumina, a supplier among others to Vanderbilt University and the Mayo Clinic6, is characterized as the Google of DNA analysis. The machines it manufactures produce 90% of wgs worldwide, while in the past it had undertaken the Genomics England Project to record the DNA sequence of 100,000 people. The size of the DNA sequencer market is expected to reach $20 billion by 2020.
Not at all coincidentally, therefore, Illumina’s executives, along with senior officials from major pharmaceutical companies, were among those invited to PMI’s presentation at the White House. The point at which high-tech companies involved in data storage and analysis, pharmaceutical corporations, and genetic companies seem to converge is primarily on the accumulation and analysis of genomic data. The highlight of “precision medicine” is, once again, the correlation of each respective disease with one or more genes, while the remaining personal data collected and analyzed in combination with big-data algorithms will add yet another layer of personalization. But is such an approach realistic based on current data?
gene therapies and pharmacogenomics
If we go to the trouble of examining the recent history of the idea of personalized medicine (and its latest re-branding as precision medicine), we find its roots in the Human Genome Project (HGP)7. The HGP, which lasted 13 years and cost a total of 3 billion dollars, was the first attempt to record and map the sequence of bases of the human genome and was completed in 2003.
Since then, based on this achievement and given the initially high cost of sequencing, methods of DNA analysis were adopted focusing only on specific parts of it—parts deemed significant for their ability to identify non-random similarities in sequences occurring within a population, and thus possible differences from other populations. These methods, known as GWAS (genome-wide association studies), adopted this “bypass” of analyzing the entire DNA and involve searching for differences in the genome between healthy individuals and patients suffering from a specific disease. The goal is to identify and locate markers of relatively small genetic variations8, which may increase or decrease the risk of developing the disease. However, the search and identification of “causal variations” at the individual level were very difficult to achieve with this method. On one hand, the genetic variations observable in patients are ultimately far more numerous than those mapped by GWAS. On the other hand, even when some of these variations are identified, it is unclear whether, how, and to what extent each of them affects the manifestation of the disease. As a result, the relatively successful mapping of causal associations was limited to variations involving monogenic disorders. The expectation of a causal correlation between genetic mutations and the manifestation of diseases was disproven for most diseases that do not belong to this category9.
With this data, many of the heavily advertised gene therapies risked falling into a void. The same applied to pharmaceutical companies’ investments aiming to exploit GWAS for the broad creation and consumption of drugs targeting specific genes for diagnosing and treating diseases, even “preventively.” Study after study proved that the change in risk assessment arising from identified variations—if and when identified—was negligible.

Source: https://www.genome.gov/sequencingcostsdata/
It is true that the methods used for encoding the genome sequence have evolved since 2003. The main measure of this evolution in next-generation DNA analysis (next-generation sequencing – NGS) is cited as the speed of extracting complete DNA sequences as well as the dramatic reduction in cost in recent years.
Supporters of personalized medicine, among whom are naturally the pharmaceutical industries, foresee, or rather anticipate, that by studying the entire genome the basic flaw of GWAS will be overcome. Moreover, the prospect of combining genomics of DNA analysis with additional -omics concerning the microbiome (microbiomics), proteins (proteomics) and epigenetics (epigenomics), as well as with data concerning daily habits and measurable biomarkers (from wearable sensors) of each individual, creates new promises for the development and promotion of drugs that are supposedly tailored to each individual and their peculiarities.
Using as an argument the low efficacy of current “conventional” drugs and the healthcare costs associated with their extremely rare side effects, pharmaceutical development companies do not merely engage in “self-criticism.” From 2012 until today, the major pharmaceutical companies have doubled their investments in “precision” drugs, with an additional increase of 30% projected over the next five years. Moreover, according to the “Tufts University Center for the Study of Drug Development,” in 2015 over 40% of drugs under development could be characterized as “personalized,” and by 2020 this percentage is estimated to reach 70%, a proportion that already applies to drugs under development for oncology. At the same time, the business interests now associated with “precision medicine” have pressured and succeeded in increasing the percentage of corresponding drugs approved by the American food and drug regulatory agency (Food and Drug Administration – FDA). In the total drugs approved for circulation in 2015, 28% concerned “precision” drugs, whereas the corresponding percentage in 2014 was at 22%. However, even this significant increase does not adequately follow the trend of rising investments in “precision” drugs.
In December 2016, with bipartisan support and with substantial contributions from pharmaceutical lobbies exceeding 1.3 million dollars, the “21st Century Cures Act” was passed in the United States. This legislation provides funding of 1.4 billion dollars for the PMI over the next decade. However, the most significant changes concern the procedures for the approval of new drugs by the FDA, particularly the acceleration of processes relating to the release of new “precision” drugs onto the market. Generally speaking, a relatively broad phase of clinical trials on random samples of the population is necessary for the approval of new drugs, in order to adequately confirm both the efficacy of the drug based on its intended use and any contraindications (side effects). However, these procedures, which concern the “average patient” due to the randomness of the sample, often led to the rejection of pharmaceutical products awaiting approval, which supposedly target specific genetic variations and biomarkers, that is, smaller and more specific subsets of the population. A year earlier, the PMI working group in its relevant report10 characteristically stated:
“The discovery of new drugs has slowed down, and only a small portion of proposed therapies are successfully translated into approved and prescribed treatments. Clinical trials of new therapeutic methods are often inadequate due to the failure to recognize the pathological heterogeneity of diseases among patients enrolled in clinical trials. In this way, drugs that are beneficial for a specific subset are rejected because the majority of patients in the trial do not respond positively to them. The discovery of deeper genetic factors underlying diseases can be used to identify the targets on which drugs act, as well as for their selective administration to patients who are more likely to have the greatest efficacy, with as few side effects as possible…”
While the causal association of genetic mutations/variations with the corresponding diseases continues to constitute, in most cases, a pious wish of geneticists, pharmaceutical companies are being released from the already weak bonds of regulations and are preparing to cash in on their investments. The significance of clinical trials is being downgraded, while the criteria for drug approval and for adding additional indicated uses will be based more on summaries of data of successful use based on the presence of specific biomarkers (such as SNPs) in patients. As for how the appropriate patient groups will be identified each time, here the complementarity of data accumulation and analysis in health with the field of pharmacogenomics becomes more than evident. Still, even if we accept that suitable patients can be identified through the analysis of their genes and personal data (the “unbiased” algorithms will take care of that), the approval and market release of a drug means much more. The promise of a “magic” genetic therapy addressed only to specific individuals (e.g., “carriers” of a “dangerous” genetic variation) will certainly also lead to peripheral sales, hence profits, among broader patient groups who will want to try it out, just in case… In this case, the framework of prescriptions should theoretically be tightened, which however would limit sales. But there is also a provision for this in the “21st Century Cures Act”: the off-label distribution of drugs (beyond their FDA-approved and indicated use)11 to insurance companies, which in turn provide them to patients through insurance programs. And if this is not enough for pharmaceutical profits, there is always the black market.
the double trap of “volunteering”
All of the above may create the question: why get involved as a volunteer in a DNA analysis program and collection of other personal health data? Moreover, the reasons for rejecting such projects may be more than obvious. Because, no matter how much those in charge promise security and confidentiality of the data, the risk of leakage or even legal disclosure of this data to insurance companies leads to nightmarish scenarios of discrimination against policyholders. On the other hand, however, the promise of targeted and more effective treatments allows some to overlook the astronomical profits of companies or the issue of privacy and potential discrimination. Even the low reliability of the treatments themselves often cannot act as a deterrent regarding their acceptance by patients. And it is true that medical issues affect us more when we are in need, and then we are in the weakest position to exercise any criticism. However, the target group of health entrepreneurs is not only patients who fall into their need, but mainly each and every one of us, as potential patients.
There is strong evidence from the other side of the Atlantic that the mass entry of workers into the magical world of genetic analyses and the sharing of personal data regarding their medical history and lifestyle has already begun to happen; however, not as a free choice or volunteering, but as employer blackmail. Obamacare provided for the “voluntary” participation of employees in so-called “wellness programs,” which employers propose in collaboration with insurance companies, with the alleged goal of “promoting employee health.” These programs usually include questionnaires about daily habits, even regarding potential pregnancy, various types of examinations, classes on obesity and smoking cessation; however, since the limits of this list are not defined, they often include genetic analyses, family medical history, and anything else that could prove useful to the employer and insurance companies. Refusing to participate in such a program increases the cost of employee contributions to insurance by 30-50%. This “voluntary” participation, accompanied by a “discount” on contributions, can be read backwards and more accurately: as blackmail for participation in exchange for a penalty, leading to a significant reduction in direct wages.
At the beginning of last March in the US – and while the biggest uproar was happening around the repeal of ObamaCare by the Trump administration – a bill (HR 1313, Preserving Employee Wellness Programs Act) was approved by the House of Representatives, which attempts to lift the formal restrictions that existed regarding employers’ access to employees’ personal health data collected in wellness programs. While the more social aspects of ObamaCare were repealed two months later, the same did not happen for employer “wellness programs.” At the time these lines are being written, the law is on its way to final approval by Congress, and if passed, it is expected to place wellness programs outside the restrictions formally imposed by a 2008 law that establishes the prohibition of discrimination based on genetic information (Genetic Information Nondiscrimination Act – GINA). With the lifting of these restrictions, apart from insurance companies, the employer also gains the right to have full named access to employee data, with whatever consequences this may entail for their future treatment by the employer himself, but also in the labor market in general. What is going to happen if this data includes DNA analyses? We leave dystopian scenarios to your imagination…
a possible restructure in medicine
Beyond the dystopian scenarios reminiscent of Gattaca-style settings (a 1997 science fiction film), the matter seems to be progressing. In March 2017, the Trump administration approved and boosted NIH funding by an additional $2 billion, among other things, to continue the PMI program. While all this is happening in the U.S., the race to collect DNA analyses and other medical data includes yet another major player. In China, the corresponding precision medicine program announced in the 2016-2020 five-year plan envisages investments of 60 billion yuan ($9.2 billion) by 2030, while the target of involving 1 million people seems easily achievable for a country with a population close to 1.4 billion.
What matters most, with the emergence of these programs, is that the collection of genetic and other medical data no longer concerns only Silicon Valley companies, such as the well-known 23AndMe, but has become a central-government policy choice. Such choices and central directions sooner or later influence both the way health and insurance systems operate and global social perceptions of health and disease.

And if such a thing seems distant—it may well be—changes in the way medicine is practiced are rarely noticed in a timely manner by those directly involved. The shift from diagnosis and treatment based on clinical symptoms to diagnosis and treatment primarily based on laboratory measurements—which moreover should be conducted “preventively”—is one such example that has had and continues to have multiple consequences on how we approach our bodies. Indicatively, the notion “I feel fine, therefore I am fine” has been quietly replaced by “I am fine, if and only if I am measured to be fine.” What will be the consequences of yet another shift toward the accumulation and analysis of personal data? How, for example, will a change in a detectable factor of genetic variation in DNA, considered to be associated with the risk of developing a disease, be perceived? From the perspective of insurance companies, the answer is certainly predictable: an increase in insurance costs. However, cost and the loss of privacy are not the only consequences. The transition from the laboratory medicine of “averages” and quantitative limits that define the good health of the “patient-mass” toward data-analysis medicine centered on the “patient-individual” is a political issue.
Rorre Margorp
P.S.: This text was written taking as a starting point the event titled “The gene of critique. Are we genetically programmed not to be genetically programmed?” which was presented on the 3rd day of the game over festival, in October 2016. For the political and ideological consequences of the personalization of health, you will find several interesting pages in the relevant issue.
Although what you have read above is from an “informative” perspective about what has been happening in the US over the past two and a half years, our purpose is not merely to be well-informed—we need that too. What matters more for such issues is timely critical action, and there are a thousand reasons for such “preparation.” Those of you who are eager can reread this text diagonally and identify how many points there are serious causes and motives for activist action. It’s about our bodies, damn it!
- National Research Council (US) Committee on a Framework for Developing a New Taxonomy of Disease, 2011. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease. ↩︎
- Related, you can read in Sarajevo 80 – January 2014: health big data. ↩︎
- The relevant information is available at: http://genomicsandhealth.org/work-products-demonstration-projects/catalogue-global-activities-international-genomic-data-initiati ↩︎
- According to estimates by those who expect wgs analyses to become mainstream in the coming years, at least in the most developed countries, 2025 is expected to see 100 million to 2 billion human genomes analyzed, bringing the volume of data to the scale of tens of exabytes (1018 bytes). This is expected to be the largest “type” of data driven for analysis. Indicatively, the corresponding forecasts for the rate of video uploads on youtube in 2025 are 1000-1700 hours of video / minute, which corresponds to 1-2 exabytes per year. ↩︎
- https://cloud.google.com/genomics/pricing ↩︎
- The Mayo Clinic took over in May 2016, with a funding plan of 142 million dollars, the organization and support of the collection, storage and distribution of the bio-samples that will be collected for the needs of the PMI. ↩︎
- Even the faces seem to remain the same. Dr. Collins, now director of the NIH, under whose supervision the PMI is running, was the head of the HGP. ↩︎
- In the techno-scientific jargon, these variations are called “snips”, from SNPs (Single Nucleotide Polymorphisms). ↩︎
- The trade of hope, regarding new drugs and corresponding therapies, often encounters disagreements that arise even “within the scientific community.” We deliberately avoid referring to disputes concerning the success or failure of this or that innovative medical treatment for one or another disease. This, after all, is nothing new. As for the success of these methods, an application of GWAS for genes that influence, not some complex disease but “simply” human height, showed that hundreds of genetic variations appear to be somehow associated with it. The resulting data could explain only 10% of phenotypic differences. Although height can easily be treated as an hereditary trait, the correlation of genetic variations with hereditary differentiation does not exceed 20%. (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2955183). ↩︎
- https://www.nih.gov/sites/default/files/research-training/initiatives/pmi/pmi-working-group-report-20150917-2.pdf ↩︎
- According to a 2006 study, the rate of off-label prescriptions in the US in 2001 reached 21%. One in five drugs, that is, were administered beyond their approved use…
Radley D.C., Finkelstein S.N., Stafford R.S. Off-label prescribing among office-based physicians. Arch Intern Med. 2006;166(9):1021–1026. Available at: http://jamanetwork.com/journals/jamainternalmedicine/fullarticle/410250 ↩︎