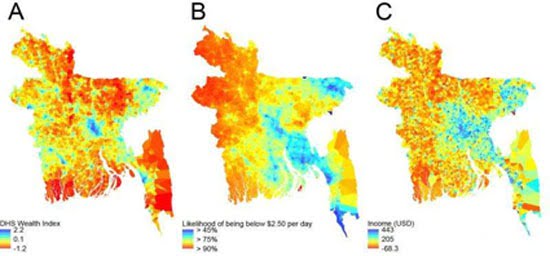
The show goes on. A typical information machine, such as a classical computer program, can successfully simulate an activity under certain conditions. The computable activity must first be understood and analyzed into a sequence of defined steps. In order to successfully simulate these steps, a program must be written - a finite and strictly defined set of rules and instructions - so that the machine can arrive at the desired result. For example, alphabetically sorting a telephone directory is an activity that can easily be simulated by a sorting algorithm. In fact, any manipulation involving symbols, mathematical operations - strictly defined logical and quantitative relationships - such as sorting or retrieving and storing structured information, can be included in algorithmizable activities. Similarly, a series of actions performed on objects, which take place as activities in a strictly defined and controlled environment (such as a factory), can be analyzed and quantified in terms of position, force, and torque applied, and executed by an electromechanical automaton controlled by a program, which can even self-regulate or adapt to its “environment” by applying feedback mechanisms.
Personal computers in office jobs, automatic control systems, and robotic arms on production lines are characteristic examples of machines from the third industrial revolution that incorporate human knowledge and techniques. We also see that such integration is only possible through meticulous analysis of the steps, rules, and instructions involved - which is also the prerequisite.
A series of “next-generation” information technologies related to artificial intelligence promise to expand the boundaries of computability/robotization, which will begin to include more and more “non-routine” (for current computing machines) activities. Technologies such as machine learning overcome the limitation of step-by-step analysis required for algorithmizing an activity. With this technology, engineers can program a machine to perform an activity by having it “study” a large number of successful instances of that activity performed by humans. Machine learning algorithms rely on the existence of a large amount of data corresponding to the activity for which the machine is being “trained.”
And how could something like this be useful?
While a conventional program can easily replace many of the tasks performed by an accountant, there are simpler, everyday tasks that are not feasible with traditional algorithms. For example, it is not possible to write a classical algorithm that enables a machine to visually recognize a chair. If one attempts to define the characteristics of a chair in a strict way - e.g., legs, arms, seat, back - one quickly realizes that there are chairs that lack some of these features. For example, not all chairs have arms or backs. If arms and backs are characterized in the program as optional, the machine immediately risks labeling a small table as a chair.
The common-sense notion that “a chair is an object designed with the intention of being sat on” is by no means easy to formulate in a classical algorithm. In the case of a machine learning program, the machine is trained by studying a very large set of different images labeled as “chair.” By analyzing a sufficiently large number of images of different chairs, the algorithm trains the machine, creating a statistical recognition model. By the end of the training, the machine will be able to use the statistical model to recognize any chair - even one not included in the training dataset. And like a good student, it will be able to learn from its mistakes and reinforce its knowledge through retraining.
Such a promising technology is not limited to the experimental verification of object detection. It is already being applied in everyday applications - in Google search and translation, in Netflix movie recommendations, in automatic recognition of the content of photos uploaded to social media, in voice commands for smartphone digital assistants, and elsewhere. Every time a Google search is followed by a visit to one of the related pages, or every time a photo is uploaded to social media and tags are added regarding its content, the training dataset of the learning algorithm expands. Subsequently, the machine becomes capable of producing correlations and content recognition for future photos or searches...
Rorre Margorp