
The term “Paradigm,” along with its companion “Paradigm Shift,” since first appearing in Thomas Kuhn’s classic book on the structure of scientific revolutions, has undergone not only the expected criticism, but also a misuse that risks rendering them useless as tools for understanding scientific practice.1 From the time when they were once considered threatening to the scientific status quo or, to be somewhat more moderate in our expressions, at least subversive to the way scientists understood themselves and legitimized their activity outwardly as the pursuit of Truth, now it is no longer rare for scientists themselves to use them as a promotional slogan for new discoveries, whether theoretical or technological. Nevertheless, these are terms that retain value, if at least one knows what they are talking about. In a move similar to that of sociology in its early steps, which placed religion at its center, analyzing it in terms of its social contexts (from Marx to Durkheim and Weber), the sociology of science, from Kuhn onward, left as a legacy the following almost self-evident(?) point: no large-scale scientific change can be understood as a movement taking place strictly within a science. And if the battle for scientific concepts transcends the boundaries of a narrowly defined rationality and its outcome is also determined by extra-scientific factors—namely ideological, social, or even political ones—then the notion of a pure science, “untainted by worldly matters,” that would function as a beacon of objective knowledge, becomes at best a chimera and at worst a mere ideological construct.2
Through the pages of cyborg we often refer to what we call capitalist paradigm shift, that is to the process of radical restructuring of capitalism in recent decades, which may have at its forefront technological developments mainly, but which ultimately reaches across the entire social field, from interpersonal relationships and the educational system to forms of political representation. We have of course borrowed the term “paradigm shift” from the field of epistemology and we use it for our own purposes and not as an exact analogy with scientific paradigm shifts.3
The question, however, arises automatically. Since the restructuring of the capitalist machine extends to so many fields, is it possible for science itself to remain outside of it? And here we obviously do not mean science from the perspective of whatever technological applications it produces, but rather its very core of theories and methodologies. In other words, can a dominant way of scientific thinking be identified, that is, a Paradigm, here and now, in today’s context? And if so, is this Paradigm singular, or does each scientific branch have its own? The easy answer to such questions would be that it suffices to look at what the latest scientific revolutions produced, on the basis of which scientists work today. For example, we could consider that the theories of relativity and quantum mechanics constitute two stable foundations of modern physics, providing physicists with corresponding conceptualizations of spacetime and causality. In the field of biology now, its central dogma, which holds that the cell is the basic unit of life and DNA the carrier of all necessary information, could be considered to constitute another such Paradigm. And thus today’s scientists, who were educated and are being educated to work on the basis of these Paradigms, can sleep peacefully. No threatening revolution on the horizon.
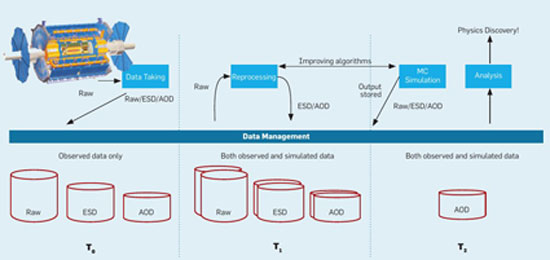
data intensity science
In 2008, in the well-known technology magazine Wired, an article appeared with the provocative title “The End of Theory: The Data Deluge Makes the Scientific Method Obsolete.” We reproduce here an extensive excerpt:
At the petabyte scale, information is no longer a matter of classification and arrangement in three or four dimensions, but a matter of statistics, for which the number of dimensions will be indifferent. It requires a completely different approach that will be free from the requirement of visualizing data in their entirety. It forces us to see data primarily through a mathematical lens and only secondarily to find their context. For example, Google needed nothing more than applied mathematics to conquer the world of advertising. It never pretended to know anything about the culture and conventions of advertising—the only assumption it made was that it would succeed by simply having better data and better analytical tools. And it was right.
The basic philosophy of Google is that “we don’t know why one specific page is better than another.” If statistics regarding incoming links tell us that it truly is better, then that’s enough for us. No semantic or causal analysis is needed. This is why Google can translate from languages it doesn’t actually “know” (given the same amount of data, Google can just as easily translate Klingon to Farsi as French to German). And it’s also why it can find which ads match specific content without knowing or assuming anything about either the ads or the content.
…
Here we stand before a world where massive amounts of data and applied mathematics will replace all other tools. Forget all theories about human behavior, from linguistics to sociology. Forget taxonomies, ontologies, and psychologies. Who knows why people behave the way they do? The point is that they do behave, and we can record and measure this behavior with unprecedented accuracy. If we have enough data, then the numbers speak for themselves.
However, the target here is not so much advertising, but science. The scientific method is based on testable hypotheses. These models are largely systems, visualized within scientists’ minds. Then the models are tested, and it is experiments that ultimately confirm or disprove theoretical models about how the world works. This has been the way of science for centuries.
Part of scientists’ education is to learn that correlation does not equate to causation, and that you cannot draw conclusions merely because X correlates with Y (which could be mere coincidence). Instead, you must be able to understand the hidden mechanisms that connect the two. Once you have a model, you can reliably make the connection between them. Having data without a model is like having noise alone.
With the emergence of massive-scale data, however, this scientific approach—hypothesis, model, testing—is becoming obsolete. Let’s take the example of physics: Newtonian models were nothing more than coarse approximations of the truth (wrong when applied at the atomic level, but otherwise useful). A hundred years ago, quantum mechanics, based on statistics, gave us a better picture—but quantum mechanics too is just another model, and as such, it is also flawed; a caricature of a reality that is far more complex. The reason that in recent decades physics has drifted toward a theoretical folklore of impressive n-dimensional unified models is the fact that we don’t know how to conduct the experiments that would disprove all these assumptions—it requires extremely high energies, very expensive accelerators, etc.
Biology is heading in the same direction. The models we learned in school about “dominant” and “recessive” genes that govern a strictly Mendelian process have proven to be a simplification of reality even coarser than that of Newtonian laws. The discovery of interactions between genes and proteins, as well as other epigenetic factors, has shaken the view that DNA constitutes something like destiny—and moreover, we now have indications that the environment can influence inheritable traits, something once considered genetically impossible.
…
Now there is a better way. With petabytes, we can say: “correlation is enough for us.” We can stop searching for models. We can analyze data without assumptions about what we are likely to find. We can feed computational clusters (the largest ever built) with numbers and let statistical algorithms find patterns that science itself cannot.
We would not wrong anyone who chose to bypass articles of such concentrated arrogance with a simple concession. The issue, however, is that the article in question subsequently became a reference point (even in a negative sense) for those trying to understand the changes brought to scientific practice and thinking by the latest information technologies for data collection and analysis at scale.
The following year, it was Microsoft itself that came to speak more “seriously” about the issue, putting its weight behind it and naming the transition process towards a new scientific paradigm, issuing a book titled The Fourth Paradigm: Data-Intensive Scientific Discovery. The fourth paradigm obviously refers to today. According to the book, science has already passed through three previous paradigms: a pre-Renaissance one that was largely empirical and simply described natural phenomena; a second one, over the past centuries, that explained phenomena based on theoretical, mathematical generalizations; and finally, a third one, from World War II onwards, that used algorithmic models to simulate natural phenomena. In today’s fourth paradigm, the center of gravity (supposedly) shifts to that point in the scientific process that lies before the formulation of theoretical models and their encoding into algorithms: to the data themselves and their collection on a massive scale, and only subsequently to the extraction of theoretical models, which in any case could also be automatically generated by “smart” algorithms, finding the appropriate patterns hidden within piles of raw data. And if this is how science (will) work, then laboratory practices must also conform to this model: large and open databases, designed based on strict standards for easier sharing, efficient and, as far as possible, automated software tools for pattern discovery and extraction, software tools that will manage the entire workflow, from data collection through to storage, analysis, and presentation; even changes to the existing system of scientific publications so that the results of various articles can be easily reproduced and articles can be interconnected not only with each other but also with digital data (here some publishers have reason to cry, but mainly academics who manage to churn out publications by presenting the same things, slightly altered and almost impossible to reproduce by anyone else).
The above you have most likely encountered under the more catchy term “Big Data”, which has a somewhat broader meaning – since it can also refer to data that does not necessarily relate to science – and which tends to “conceal” the fact that it is not simply about large and heterogeneous data, but precisely about an attempt to re-conceptualize what ultimately constitutes the usefulness of data and how (one should) draw conclusions from them.
how “given” are data after all?
These are the things that those “visionaries” from the scientific elite, who are at the forefront of technological developments, have to tell us. However, taking at face value the way engineers and scientists themselves understand and present themselves is the surest path to understanding nothing of the dynamics driving any developments. Let’s start with the very basics, with a few observations regarding the terminology used. Are Big Data a new paradigm? Are they even a paradigm, in the epistemological, Kuhnian sense of the term? If one flips through “The Fourth Paradigm,” they will struggle to find even a few references to the so-called extra-scientific factors shaping the “new paradigm.” In fact, the complete absence of any reference to anything that seems to carry the “grime” of the socio-political realm produces a description of the evolution from the first, pre-Renaissance paradigm to today’s as if this evolution were an internal and self-sufficient movement of the scientific spirit in its quest for Knowledge. Thus, we are not dealing here with a minor oversight or careless use of the term “paradigm,” but with the complete intellectual reversal of what Kuhn attempted to describe. We said something at the beginning about the misuse of the term. Behold a blatant example…
Small harm, one might say. The fact that scientists are unable to understand and use terms outside their field (oh, what a surprise, really!) does not necessarily imply the actual absence of a paradigm shift that may currently be underway. We will return to this topic later. For now, we will limit ourselves to one more terminological observation. If we assume (an assumption that is well-founded) that there is indeed an observable turn toward mass data collection and algorithmic analysis, then what is the relationship of this new direction to the immediately preceding scientific models of thought and practice, those which it is supposed to overturn? A key component of paradigm changes (let’s reiterate, as Kuhn described them) is also the inability to make an “objective” comparison between the old and the new paradigm; in other words, an asymmetry that appears to exist between them, even at the level of interpreting basic concepts, such that simple communication between adherents of each paradigm becomes problematic. Each paradigm lives within itself, constituting a comprehensive worldview (with corresponding ontological extensions), with its own concepts, its own priorities, and ultimately its own values. It is rather evident that any turn toward the mass use of data does not constitute, in no case, a cut of such depth in relation to the previous algorithmic phase of science that the term paradigm would be needed to describe it. Essentially, it involves the same conceptual arsenal, only this time aimed at… whatever moves, and moreover in real time. If the term paradigm must be used, in its epistemological sense, then the birth date of today’s paradigm is located considerably earlier, at least a century back, in the judgment of mathematicians at the beginning of the 20th century.
Regardless of any “scholarly” discussion around the concept of the Paradigm, Big Data, even as a new methodology (and primarily as a new “problem to be solved”), seems to have come to stay. And the enthusiasm (along with money and research programs) is not lacking. We will momentarily turn a blind eye, pretending not to see the dance of funding, conferences, and academic positions being set up around them. From a purely epistemological perspective, therefore, the advantage of Big Data compared to previous scientific methods (supposedly) is… accuracy and objectivity (what else!). And why is that? There is a simplistic logic that can easily translate quantitative magnitudes into qualitative criteria, and surely this has also lent its hand here. More data means more complete coverage of the field being studied and a more thorough examination of all possible explanations for a phenomenon. However, it is not only the data themselves and their size that play a role. If the volume of data necessitates the use of algorithms to handle them, then these algorithms (again, supposedly) will be able to “learn” so as to find correlations on their own or even produce the optimal theoretical models that best fit the data. By eliminating pre-constructed theories, we are also freed from the burden of human subjectivity that these theories inherently carry by definition, thus ultimately producing more objective theories.
The above is quite reasonable. Only that blessedness is the enemy of critique. The fact that there are no “raw,” “unprocessed,” and “objective” data is a first objection here. Even the simplest data that can be directly obtained from sensors already presuppose that “someone” has made a specific choice regarding which of them should be taken and how they should be measured. How “objective” is it to measure the strength of a friendly bond through Facebook likes or the electric charge of a particle through its interaction with this or that material in an accelerator? It depends! To begin with, on whether the example (i.e., the theory) says that charge or likes are something worth measuring. In more philosophical-epistemological terms, this is what has been called the theoretical loading of every experimental observation, and it is not even a new finding. But for the devotees of Big Data, these are minor details, although of course it is understood that the more suspicious ones know that data without theory simply cannot exist.4
A second objection is less obvious and has to do with the fact that using massive data may not only fail to improve objectivity, but may actually work in the opposite way! When we are talking about such enormous volumes of data, finding regularities and correlations may not be a rare occurrence at all, and thus the problem shifts to which of all the discovered correlations is more “real” than the others. With a little tweaking of parameters, we assume that everyone will be able to find exactly what they are looking for. There is even an “anecdote” circulating in the relevant literature, concerning the fact that it was “proven”, using massive data, that an American stock market index exhibited a strong correlation with butter production in Bangladesh. Conclusion? With a strike in Bangladesh, the American stock exchange will collapse. Long live chaos theory!
And beyond the stage of their analysis, massive data are prone to the “invasion” of subjectivity even during their collection; and indeed, the more massive they are, the more prone they become. The reason? It’s called representative sampling (you remember the “Big Data” of electoral polls, right?), which becomes increasingly problematic the broader the range that needs to be covered, and which simply does not exist when dealing with “orphaned” and “random” data, such as social media posts.
the disappearance of theory (or the spectacle as theory)
In any case, our purpose is not to ridicule the claims of those who see in Big Data some new super-paradigm; claims that, in any event, have a strong propagandistic element. Any real changes that may accompany a new model of scientific thinking and practice, even if it does not constitute a Paradigm in the strict sense of the term, are of greater interest. It’s just that often, to talk about something, one must first talk about what that something is not. So, let us suppose that we are not dealing with any Paradigm; and let us suppose that Big Data is neither the lens of objectivity nor will it free us from awkwardly subjective theories. Does this mean that physicists who have learned to work in the classical way, formulating differential equations (and passing them to some simulation program), can sleep soundly? We are not so sure about that.
Even if the need for theoretical models in science does not disappear, it is not at all unlikely that the introduction of essentially tailor-made principles for data management could lead to a more multi-layered stratification of scientific potential. In more “cynical” and realistic terms, a restructuring of the division of labor within the ranks of scientists, where the masses will handle data using little – highly standardized smart software packages, and an elite of “privileged” theory builders, who perhaps do not even have an overall overview of their entire field. Also, it is not unlikely that such a division of labor could have epistemological consequences in turn. Once theory is deferred, inscribed, and encoded in the early stages of a long data processing chain, it will not be easy (or permissible) for cracks to appear that threaten to collapse the entire chain. Which certainly does not exclude (and the nature of software rather encourages) the frequent emergence of competing theories, creating their own parallel and coherent conceptual “ecosystems”, each with varying degrees of success and lifespan.
Now, staying at the level of the scientist – mass, how could one understand the activity of such a worker of the (scientific) spirit, who would engage in the hunt for rapid discovery of correlations, possibly indifferent to the hidden mechanisms that produced the correlations? A clarification first. One could argue that the rapid discovery of correlations (the emphasis on “rapid” here) is not even a demand of scientific research and anyway in large scientific programs it is considered self-evident that data analysis needs some respectable time to yield results. This is correct and we would add that the demand for speed comes mainly from commercial systems of big data analysis that focus mainly on trend prediction, where a deviation of the order of a few fractions of a second can make the difference. Typical example are the algorithms that run on stock exchange data or the “auction” algorithms of online advertisements. Correct, but… this does not mean that such “humble” profit motives, together with the corresponding techniques that feed them, cannot cast their shadow over the “pure” scientific spirit. Only naivety and historical ignorance can justify the perception that wants the “high” spirit of science to move in an immaculate sphere of ideas, unaffected by the very humble and daily aspects of social life. The examples of scientific ideas that had very humble origins are not few.
And we come to the issue of (intended or imposed due to specialization) “indifference” towards the mechanisms of producing correlations. The philosophy and sociology of science, in their development and due to certain more “heterodox” theories that challenged naive notions of science as a faithful representation of reality, were forced to create certain fundamental distinctions regarding the meaning of explaining a natural phenomenon.5 One such fundamental distinction is that between the observed phenomenon itself, its representation in the form of specific measurements, and ultimately its interpretation in the form of theories. One realizes that for such a distinction to be made, the relationships between the three poles of the triangle—phenomenon – representation – theory—are not at all obvious. Who measures what, under what conditions, how measurements are interpreted, how many coherent theories can interpret the phenomenon—these are only some of the issues that have been raised, without easy answers. The dogma that says “a correlation is enough for me and I don’t care about theories,” apart from the problem of finding the most “real” correlation among those mentioned above, also constitutes a movement of absorption both of the phenomenon and the theory into the representation of statistical correlation, at least for those (who will) work at this level. And if this is combined with the tendency shown by large scientific programs, such as those that the Big Data methodology aims to handle, to be constituted as long chains of both material and “immaterial” (see software) devices, with hundreds of scientists working in different parts of the chain, then the mystification of the examined phenomena is just one step away. It is probably not coincidental what is already observed in experiments such as those at CERN—which operate exactly with such a logic—with participating scientists expressing themselves in a language that has similarities to that of apophatic theology!6 A computationally reconstructed trajectory of the Higgs boson as a mystified representation: did someone say that spectacle has nothing to do with the fields of science?
Speaking in terms of the Italian workerist reading of Marx, positioning the machine (analysis of Big Data) at the center of scientific practice, as the universal and dominant means of mediating scientific thought, could be encoded in the phrase the real subsumption of science under capital. Its formal subsumption can be traced, if not earlier, then certainly already from the 19th century, when its control and external organization were primarily undertaken by the state, through universities, and by businesses, through their laboratories. The internal reorganization now being attempted, based on economic (both within and beyond introductory) performance criteria of the machine and social criteria of spectacle, also constitutes a stage of its capitalist maturation. From this perspective, therefore, the fourth paradigm does not constitute a beginning (of a new scientific period), but rather the completion and organic integration within the capitalist cycle of what was once the cornerstone of classical, bourgeois liberalism: the independent scientific spirit. Precisely the model of science that fits optimally within the dictates of a postmodern, spectacular world, without grand narratives…
We are not among those who will mourn and shed tears for the fading aura of the traditional scientific spirit in the face of the machine’s onslaught. Such tears we leave for the contractors of orthodox “Marxism” – who still struggle to digest how closely related it is to bourgeois liberalism. Nor do we have the disposition to underestimate the new model, from the perspective of its epistemological value. Those who rush to prejudge its poverty in producing captivating theories might be wise to first take a look at similar objections raised by certain mathematicians in the early 20th century, when the algorithmic Paradigm began to emerge in mathematics (though whether this was indeed a Paradigm in the Kuhnian sense). What certainly concerns us, however, is our own devaluation, through our transformation into productive and consumptive appendages, at the ends of an opaque and mystified mechanical chain. And we lack any hand of sympathy to extend toward the scientist-mass, as long as he persists in listening to its alienating bomb. We pay for his alienation even more dearly.
Separatrix
- For a more tangible example of concept abuse, one can see what the word “revolution” has landed in the hands of advertisers. Not to mention the “political specialists” of the kind, whom one encounters in every corner of our parts. ↩︎
- Kuhn’s work is considered a landmark mainly in the Anglo-Saxon world. Continental Europe (mainly France) had already produced similar work (though less well-known, for obvious reasons) before Kuhn. See the book by Dominique Lecourt, Marxism and Epistemology: Bachelard, Canguilhem and Foucault. ↩︎
- See related article in issue 4 of Cyborg, On Changing Paradigms ↩︎
- The argument about theoretical bias is not unknown (even if expressed in different terms) to scientists working with “intelligent” machine learning algorithms, that is, algorithms that derive conclusions-theories from data. The purpose of such an algorithm is first to be trained on some initial data and then to be able to draw the “correct” conclusions using new data as well. For example, if an algorithm has learned to recognize cats by “seeing” some initial photographs, it should be able to recognize them in photographs it has never “seen” before. And here comes the interesting part. All these algorithms always start with some kind of “bias” regarding which theories (e.g., rules for recognizing cats) they will learn or, to be more precise, which classes of theories they will be able to learn. And not only that, but it is known that a completely unbiased algorithm would only manage to learn the cats from the initial photographs and nothing else. Upon encountering any new photograph it had never seen before, it would go… haywire, producing one thing instead of another. ↩︎
- To be fair, such concerns about explaining phenomena (the role of the senses and their reliability, their multiple interpretations, etc.) were not the exclusive privilege of philosophy and the sociology of science, as these have been shaped in recent decades. If one wants to go back far enough, one could reach the ancient sophists and skeptics. ↩︎
- For this topic, see the rather dry and unwieldy, but relatively useful book by Knorr-Cetina, Epistemic cultures: how the sciences make knowledge. ↩︎