
«The issue is not that laws do not have power, but that the nation-state does not have power. It is not possible to regulate the internet.» Date: mid-1990s, when the internet was in a phase of takeoff and global expansion. Source of the statement: Nicholas Negroponte, founder of the famous Media Lab at MIT and considered one of the gurus of new technologies. Like so many other similar overly optimistic statements of that era, this one also ultimately proved remarkably inaccurate and is now used in internet-related discussions, sometimes with a touch of nostalgia, as a typical example of a mistaken prediction stemming from an era of naivety. The fact that those supposedly competent authorities on technological matters are precisely the ones who so systematically fall into such errors “should” have already created that social memory which would treat them as inherently unfit to speak about anything beyond the narrow confines of their laboratories. Yet memory is not the strong suit of modern western societies.
The fortunate thing for such special cases is that they have a fairly elastic conscience that allows them to bend and fold whenever reality proves to be less than their fantasies. Jerry Yang, founder and former CEO of Yahoo, is such a case. In 2000, when Yahoo still had the aura that Google has today, Yang received a call from French courts asking Yahoo to take the necessary measures to prevent access within French territory to neo-Nazi content pages that it hosted on its servers. Yang’s first reaction followed the ideological lines drawn by Negroponte: the internet is by nature “anarchic” and cannot be regulated because some judicial fiat demands it. After a not long-lasting legal dispute (where it was proven that it is indeed possible to geolocate users, contrary to what the company had claimed), Yahoo was forced to fold. Not only did it comply with the demands of the French state, but just a few years later it would directly cooperate with the Chinese to identify dissenting journalists. The unfortunate thing for those who do not have vested interests revolving around the internet and its technologies – that is, for its “ordinary users” – is that the relevant discussions take place on the basis of an impressively massive and deep ignorance regarding its structure. Therefore, quite unsurprisingly, they end up being discussions utterly devoid of content, floundering in a chaos of constantly recycled ideologies, inspired by technofetishistic perceptions that mistake their desires for reality… only to be swiftly crushed when the time comes to confront that reality.
If one takes into account the fact that the structure and operation of the internet are not at all difficult to describe and understand, even in broad terms, then this ignorance can only be, at least in part, deliberate—as is also the case with so many other scientific and technological concepts which, although accessible in their basic conception, are ultimately surrounded by the aura of a quasi-mysticism. To the simplest question of “what exactly is the internet?”, the best answer one can hope for, often even from supposed experts, is that it is a distributed communication network between computers. Such simplistic answers give rise to related ideological notions about the decentralized and therefore anarchic structure of the internet. However, the internet, although it does indeed have some elements of decentralization, also has many others: such as a hierarchy with largely invisible key players at its top. And something more. There is no single internet that simply passed through an experimental initial phase to eventually take the form we more or less all know(?) today. It has undergone a series of significant structural reorganizations—reorganizations that were articulated with broader social and (geo)political pressures. One of these is taking place precisely at this moment—if it has not already been completed. The aftershocks of this tectonic shift have become evident in recent years through various “scandals” regarding the extent of all kinds of technical surveillance and monitoring, accompanied by a sense of disappointment over the loss of an era of innocence. Yet this café-style, repeatedly expressed disillusionment is the fate of those who revolve around the internet’s “tower,” treating all kinds of specialists as ominous gatekeepers. Time, then, for a look under the hood.1
1st phase: in the beginning there was the ARPANET
It is rather well known that networking technologies were born through the research of the infamous ARPA, the research service of the American Pentagon. What may not be so well known is that the initial motivation for investing in such technologies was not purely military. During World War II, the first electronic computers had managed to “prove” their usefulness in performing scientific calculations on a massive scale, and after its end, they had begun to be applied in research fields outside the purely military. However, entering the 1960s, a serious economic resource management problem emerged for ARPA. The Cold War may have ended, but it had left as a legacy a new model for conducting scientific research, which, in its basic lines, survives to this day: instead of technological research being conducted based on the fluctuating inclinations of some companies or individual inventors, and basic research being the privilege of some university institutions, they became strategic areas for resource investment by the state itself in order to constitute the spearhead for purposes of both capitalist development and geopolitical expansion. The era of little – fairly free scientific activity had ended; however, the era of large budgets and the mass, bureaucratic production of technoscientists had begun. As the key arm of this new research model, ARPA had undertaken to fund several computing centers in various American universities and institutions. The problem that eventually arose was the continuous pressure on ARPA for new computing machines, the cost of which was still enormous at that time. Instead of yielding to this pressure, ARPA chose a different path: the development of networking technologies for these supercomputers so that they could share their resources and have remote access to them, even for researchers who did not have direct, physical access; an absolutely logical approach from the perspective of capitalist management, especially since these extremely expensive computers simply remained idle for long periods of time.
The connection and communication between two computers was not a problem from a technical point of view. The real problem was how multiple computers could be integrated into a network so that each one could potentially communicate with any other. Directly connecting all computers to all others would require an extremely large number of lines and would ultimately have prohibitive cost. On the other hand, the model of telephone networks, which up to a point had achieved a dense degree of interconnection, had another disadvantage: it operated on the logic of closed circuits. In every call, the two devices had to create a closed circuit, with the result that the lines participating in this circuit could not be used by other users until the call was terminated. For computer networks, however, it was important that lines could be used by multiple users simultaneously so that a computer could make its resources available to these users at the same time. 2
Fortunately for the engineers of the time, the solution already existed and they did not need much time to discover it: it was called telegraph networks. Telegraph networks had been operating for decades based on the logic of geographically distributed nodes and could send a message from any of their offices to any other without direct interconnection lines between all nodes. What their employees did when they received a message was to examine the final target address and forward the message to the next node that seemed closer to the final destination. Speaking in Greek geographical terms, a telegram from Thessaloniki to Chania, upon reaching Athens, might not have been able to be sent directly to Crete due to lack of direct connection. However, it could be forwarded southward, for example towards Tripoli, where the same process would be repeated until it eventually reached Chania. Another advantage of telegraph networks was their tolerance for large traffic volumes. When certain lines were overloaded, a telegram could be stored for as long as needed until the lines opened up and it could be forwarded. This operational model was called the store-and-forward model. By the 1960s, telegraph networks had mechanized the work of forwarding employees and their model had already inspired military-type research. The prospect of a nuclear conflict had sparked research towards developing telecommunications infrastructures resistant to nuclear strikes. It was within the laboratories of RAND (an American think tank with close ties to the Pentagon) that telegraph networks were algorithmically modeled, precisely because they were considered resilient to failures – for example, if the Tripoli node went offline, a message could be forwarded towards Sparta and thus the network could continue to operate, albeit with reduced capabilities. For various reasons, RAND’s early research did not progress to the implementation stage, but was discovered by ARPA engineers a few years later, when they were called upon to solve their own networking problems. One difference compared to telegraph messages was that digital ones, in cases where they were quite bulky, could be divided into small packets, these packets could be sent one by one, and the original message could be reconstructed from them at the final destination. This technique allowed the sharing of lines so that a large message would not occupy a line entirely until it was sent, since packets from different messages could alternate on the line and travel “simultaneously”, albeit at slower speeds. This specific technique was eventually named packet switching and is still at the base of most computer networks, including the internet.
The first computer network was put into operation in the late 1960s, under the name ARPANET, and included only four academic nodes. During the following decade, nodes (always academic and research-oriented) continued to be added to ARPANET, but applications also emerged that went beyond the original designs for sharing computing resources. One of these was the famous USENET, a kind of primitive (by today’s standards) electronic forum where discussions covered a wide range of topics, from scientific news to music and cooking recipes. However, the greatest success seems to have been achieved by email, which first appeared at that time and allowed asynchronous but fast communication.
Nevertheless, pivotal for the further development of the structure of computer networks was the emergence of the Internet itself. Strictly speaking, ARPANET was simply a network and not the Internet. Relatively quickly after its emergence, both companies and other government services, such as NASA, developed their own networks, more or less based on the ARPANET logic. In an effort to “lock in” their customers to their own ecosystems, some companies even provided their own hardware and software for accessing their networks, which, however, were incompatible with other networks. To prevent fragmentation into isolated networks, ARPA rushed to develop a series of communication protocols, such as the well-known TCP/IP, which every network had to respect in order to be able to connect, via appropriate nodes, to the rest of the networks. The result: the emergence of inter-networking, that is, the ability of networks to be hierarchically structured and to communicate with each other through higher-level nodes whose job is to “stitch” together the individual networks.
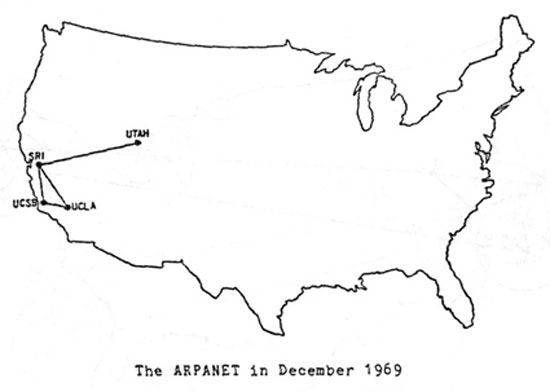

Phase 2: Internet for the masses
Until relatively late, even into the early 1990s, the concept of browsing the internet was something unknown, although connected computers were already hosting considerable material, mainly in the form of electronic documents. A user who wanted to search for information on a topic could not simply visit a search engine, as such did not yet exist—there were some basic cataloging services, but their entries were not interconnected in any way. The best way to find a document was to already know on which node it was located. Moreover, even if one knew where to connect, the connection was not made through a graphical interface, like those later offered by browsers, but through special programs that required somewhat more specialized knowledge. It was the well-known World Wide Web (www) that changed the internet user experience. Strictly speaking, the www is not a technology, neither at the hardware nor at the algorithmic level. It is not even a type of protocol. Rather, it is a widely accepted agreement regarding the way internet texts are structured to take the form of hypertext—texts that allow some form of interaction, most importantly through hyperlinks that refer from one text to another. While not being an ingenious idea itself, the www nevertheless opened up two very important directions. First, by being a unified standard, it formed the basis for the development of browsing programs (web browsers) that could present the content of any page, even to a relatively inexperienced user. Second, the hyperlinks embedded in the texts allowed for the development of algorithms for automatically scanning the internet (since it is possible to automatically jump from one page to all its references), and therefore for more efficient mapping of it.
Until the mid-1990s, it was not at all obvious that the internet would prevail as the obvious choice for electronic communication and information. It remained just one of the possible options. As already mentioned, several companies had invested significant amounts in developing their own networks, through which they offered their customers considerable content and communication capabilities (Microsoft’s MSN was one such case). The open nature of the internet, with public access, as well as the www which provided the ability for both easy navigation and relatively easy content provision by anyone who could afford a few cheap servers, eventually imposed the internet as the de facto choice.
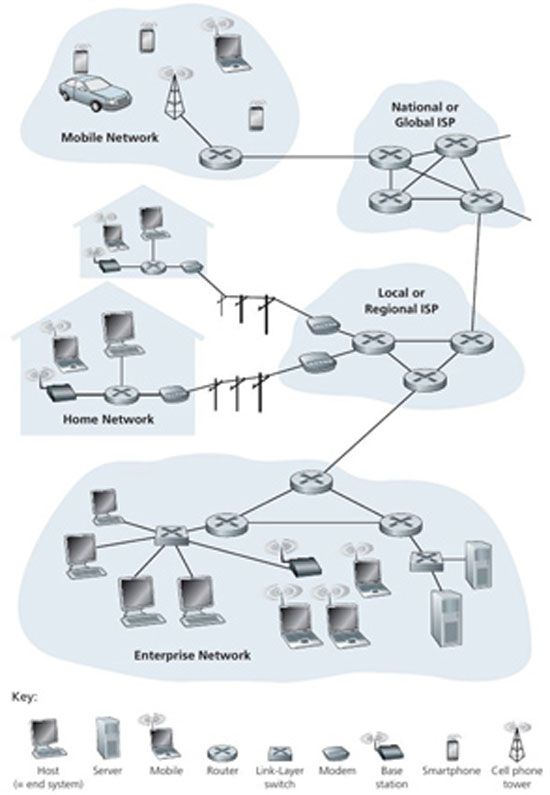
The result was also a structural change in the internet. Once its use spread beyond academic centers and reached homes, new infrastructures had to be established. This is where Internet Service Providers (ISPs) emerged. Unlike the closed networks of other companies, ISPs were not (and are not) responsible for providing content or services. Essentially, they lend, in exchange for a fee, their physical infrastructure— their lines and centers—and leave it to the user to find whatever they want or to use whichever services are offered on the internet (such as e-mail, although this service is often part of the connection package). However, no ISP has the resources to lay lines across the entire planet. Instead, they exploit the hierarchical organization capabilities of the internet. Local providers are responsible for a specific geographic area covered by their lines. For any traffic between nodes within this area, their own network suffices. Otherwise, if the two nodes are in different local networks, the traffic must “move up,” that is, pass through the networks of providers with broader coverage, whose nodes are strategically placed at various points around the globe 3 (the exchange of traffic from one network to another takes place through special nodes, the so-called Internet Exchange Points, IXP). These higher-level, globally-reaching providers constitute the so-called backbone of the internet or, otherwise, make up the tier 1 network.
And here the question arises: who owns the backbone of the internet. And who owns it now; The lower-level ISPs, as responsible for the “last mile” of the lines reaching end users, originally belonged to private companies. For a while, the state-owned ARPANET effectively played the role of the backbone. At some point, around the mid-1980s, this role had been taken over by NSFnet, the network established by the American National Science Foundation (NSF) which was also state-owned. About a decade later, when it became clear that the internet would prevail over the remaining closed networks, the American government realized it was facing a vast area of commercial exploitation. It therefore proposed the complete liberalization of the internet, that is, the relinquishment of any rights it had held until then, in a move that created considerable noise and stirred reactions, mainly from individuals in the so-called cyber-libertarian community,4 who until then had assumed that the American state would continue to maintain a passive stance regarding developments around the internet.
The retreat, however, was complete and abrupt. The American state withdrew not only from the backbone of the internet but also from other core functions, such as the naming of websites. The real address of a webpage—in the sense that it is understandable by the internet’s forwarding machines, the routers—is simply a series of numbers, known as an IP address. The considerably more readable and accessible addresses used today by users are nothing more than a user-friendly translation of these IP addresses. For this translation to occur, a “dictionary” that makes the correspondence is required. This dictionary is stored on special servers (DNS servers) around the planet (local ISPs usually keep copies of the dictionary on their own servers to speed up the translation for their customers), and there are services responsible for maintaining and updating it. Before the internet’s liberalization, the person essentially responsible for this dictionary was Jon Postel, an academic regarded at the time as an internet guru, who oversaw the central DNS server. When he learned that the DNS infrastructure too would be transferred into corporate hands, he decided to react to this “alienation” by reclaiming control through technical means that need not be described in detail—we simply note that he “tampered” with the so-called root, the central machine. The following telephone conversation is between Postel, an official from the university hosting both him and the central DNS server, and a government official, as it took place the next day, in 1998:
– [Gov.] Jon, what’s happening with the Internet Root?
– [Postel] Just running a test.
– [Univ.] What are you doing, they say?
– [Gov.] Jon, you don’t have the legal right to run tests. You can’t run a test without DARPA’s approval. You’ll find yourself in trouble and continue. Both you and the university will be held accountable.
– [Univ.] Damn it, lawsuits will start raining down from the impact on commerce. The university could go bankrupt. Jon, you must stop immediately.
– [Postel] Sorry. I was just running a test. I didn’t mean to cause any problems.
– [Gov.] We don’t want to get you in trouble. Fix things back the way they were, and we’ll say it was a test.
Somehow like this, ingloriously, “with a bend,” the heroic era of the internet came to an end, which was built with ARPA money and with the passion of many geek postgraduate students.
Phase 3: A multipolar internet
All of the above is not a secret and can easily be found even in technical manuals. The impression that is created is that the internet, at least as far as its infrastructure is concerned, has now entered a mature and stable period, constituting a homogeneous and global medium, with language being the main (cultural) barrier between national networks. Any competition that exists should therefore take place mainly at the level of new applications and services – which will be the next social network that the “netizens” will rush to provide their personal data to, or in which online landfill on demand video will they choose to square their eyes? A little further from the (many) spotlights of publicity, however, a struggle for control of the internet infrastructure itself has been underway for some years now, and indeed at various levels.
The internet organization diagram we presented above shows how ISPs are organized in hierarchical levels. First note: users naturally know which ISPs operate at the lower, local levels, since they pay them for internet access. However, although there is some information available about higher-level ISPs (though not confirmed by the ISPs themselves), no one knows exactly who they are, and even less is known about their infrastructures and the exact costs they have agreed upon for transferring traffic from one network to another, as this information is protected by so-called non-disclosure agreements. 5 Second note: there is an interesting element in this diagram that was not present in earlier editions of the book from which we borrowed it. 6 In the upper right corner, at the same level as tier 1 ISPs, so-called content network providers have been added, with Google as an example. In simple terms, what is essentially happening is that companies like Google (as well as Facebook and Amazon), due to their enormous traffic volume demands, instead of using the corporate packages offered by ISPs to reach the outside world, are promoting an alternative model: their ascent, on their own terms, directly to the very source of global internet traffic, by participating in the construction and deployment of new optical fibers (often submarine) across the entire planet. 7

From the moment that large segments of this new infrastructure aim to serve exclusively the traffic of the involved companies, a (seeming) paradox emerges here. Companies of this kind (but not ISPs) are at the forefront of the battle to defend the principles of net neutrality. In technical terms, net neutrality means the following: data packets arriving at an ISP’s node (router) must not be subject to discrimination based on their content (such as blocking or reducing/increasing their speed/priority). A packet containing video data and a packet containing email data must be treated neutrally and equally. Supporters of net neutrality – which was legally protected until recently, although legislative reversals have already appeared in the U.S. – argue that its potential abolition would create an unfair high-speed internet for the “haves” and a low-speed one for the “have-nots.” The term “haves” (and “have-nots”) here refers to content providers (who should, if they can, pay more if they want their traffic to receive preferential treatment) and not to users, who are anyway subject to discrimination depending on their connection package – but not on the content they consume.
Netflix, a well-known provider of internet television junk, recently discovered what it means in practice to abolish net neutrality, when Comcast, perhaps the largest American ISP (for residential users), chose for months to impose restrictions on the video packets it received from Netflix’s platform. The reason? Indeed, Netflix had paid its own ISP for the volume of traffic that was its responsibility, but when all that traffic landed on Comcast’s network during peak hours, the latter was unable to cope, since its commitments to its customers regarding provided speed were based on previous usage models that did not anticipate such a volume simultaneously. Comcast should have upgraded its network, but since Netflix was the cause of the upgrade, then the latter owed (according to Comcast) to pay a bit more – which eventually happened, despite reactions, since Comcast holds an almost monopolistic position and could impose its will.
The reason why content providers are so fervently in favor of net neutrality is precisely to avoid facing such unpleasant surprises. Conversely, ISPs are pushing for its abolition so they can adapt to new usage models – from their perspective, a blanket upgrade of their networks with flat-rate pricing doesn’t make much sense, since the increased traffic is due to specific content providers. In recent years, however, the enthusiasm of Google and its allies in defending neutrality appears to have waned, although their stated position hasn’t changed. Being more foresighted than Netflix, Google chose the difficult path we already mentioned: attaching itself, through its own infrastructure, directly to the backbone of the internet. This simply translates into a de jure defense of net neutrality and a de facto abolition of it; an abolition that cannot be legally challenged to the extent that it is not obligated to accept traffic from other networks into its own. Within its own network, it naturally has the freedom to maintain neutrality – packets from youtube videos (owned by Google) are treated equally with those from gmail. The letter of net neutrality can be upheld, but its spirit has already departed.
There is one more factor that acts catalytically in the erosion of net neutrality and, more broadly, in the fragmentation of the internet: the value that this vast volume of data passing daily through fiber optic cables has acquired. One dimension of the issue is, of course, economic. The algorithms for constructing all kinds of user profiles operate under a regime of constant hunger for new data—and this data clearly prefers to circulate within well-guarded online platforms. The other dimension is (geo)political, in the full sense of the word. As for these personal data themselves, no serious state on the planet is willing to create (and moreover, for free) databases of its citizens that would be located within the territories of adversarial states—and this territory is almost invariably the U.S. The banning of certain social networks constitutes only the first line of defense, and not even the most sophisticated one. The alternative is to allow such social networks, but to legally require that the servers hosting the relevant databases be physically located within the country where the respective social network operates, and to prohibit the “migration” of data to foreign servers. The most radical solution, however, strikes directly at the internet’s infrastructure (ISPs, fiber optics, DNS servers), and an example of this is the so-called fiber-optic silk road.
The ease with which American (and allied) intelligence services can collect such a massive volume of data is due (as revealed by Snowden’s leaks) precisely to the fact that they do not target individual users, although of course this capability is also in their arsenal. On the contrary, they had installed “taps” at central nodes of the internet backbone from where they massively pulled all traffic. And if this issue is serious when it concerns data of ordinary users, one realizes that it becomes critical when data potentially containing corporate or even state secrets passes through such compromised nodes. Encryption is supposedly a solution; and indeed it can work. For a while, at least. The field of cryptography resembles a race to see who will first break the opponent’s code and cannot offer a guaranteed solution. For countries like China (and the BRICS) that have both the motivation and the required depth, the solution lies in developing new, inaccessible internet infrastructures, potentially controlled independently of the West. This means thousands of kilometers of optical fibers, both submarine and terrestrial, often running parallel to the new Silk Road that China is already implementing. Chinese investments, of course, are not limited to abroad. At this moment, China is considered a country with high connection speeds and continues to invest in its internal infrastructure. With the significant addition that the Chinese internet is not the internet. Traffic into China is continuously filtered by a sophisticated digital firewall developed on central nodes of the Chinese backbone—again, this is possible precisely because of the hierarchical structure of the internet—and simply discards “undesirable” packets (e.g., traffic originating from websites related to Taiwan’s independence). The idea that the internet and its innovations can only flourish on the grounds of “anarchy” and open, “democratic” systems should probably be put to rest once and for all in the history books.
The Chinese perception of the internet may seem “barbaric” to the “free” eyes of the West. It is not our purpose to defend this perception. However, if we had to put more quotation marks, we would put them around “free” and not around “barbaric.” The kind of active filtering that the Chinese state engages in is by no means the only way to regulate the content that reaches internet users. And it may not even be the most sophisticated, at least according to some analysts. 8 On the contrary, at the higher end of the scale of technical interventions in internet content (at least so far) are the techniques of direct and aggressive participation in the production and circulation of new content. The example of the recent American elections is recent; and we are not referring to the alleged Russian finger, but to the targeted political advertising campaigns that effectively created different “internets,” depending on the target – propaganda campaigns or even public defamation are also considered part of these techniques. 9 Perhaps, after all, the Chinese state will indeed need the guidance of the West in the future. If this is the “free” version of the internet, then it is questionable who ranks higher on the scale of “barbarity.”
We will conclude with this: there is no longer a single, homogeneous internet. This is an outdated perception that remains alive only due to intellectual inertia. What exists is a fragmentation into federated (or non-federated) internet fiefdoms and domains, whose territory and characteristics are determined by monstrous economic interests and by geopolitical frictions of tectonic scale. Those who insist on perceiving the internet as a playground of free play may soon discover that it is simply “cannon fodder.” Or otherwise, data for the optical fibers.
Separatrix

- To avoid tiring with continuous references, we list here some sources from which we drew material: «Computer: a History of the Information Machine», Campbell-Kelly, Aspray, Ensmenger, Yost, Westview Press, 2014, «Inventing the Internet», Abbate, MIT Press, 1999, «Access controlled: the shaping of power, rights, and rule in cyberspace», Deibert, Palfrey, Rohozinski, Zittrain (ed.), MIT Press, 2010, «Who controls the Internet?: illusions of a borderless world», Goldsmith, Wu, Oxford University Press, 2006, «Computer networking: a top-down approach», Kurose, Ross, Pearson, 2013. The last one is of technical nature. ↩︎
- The analogous example in telephones would be the requirement for a telephone line to be able to handle simultaneous calls. Until a certain point in time, the closing of circuits in telephone calls was done manually by employees at telephone exchanges. The work of these predominantly female employees is sometimes depicted in old movies, where the user first calls the exchange, requests to be connected to another user, and the female employee closes the circuit by inserting cables into sockets on a panel. ↩︎
- This description is relatively simplistic. There may be intermediate levels in the hierarchy or a national provider may also hold some international lines. The key point here is the existence of a hierarchical organization. ↩︎
- See also Cyborg, vol. 9, “The cyberlibertarian ideology and digital commons“. ↩︎
- From what little is known, some of their names are (Level 3, Comcast, AT&T, Verizon), as well as the fact that several times they do not impose any charge for the network traffic between them (the so-called peering) if the volume of traffic they receive is roughly equivalent to the volume they send. ↩︎
- “Computer networking: a top-down approach”, Kurose, Ross. The figure is in the 6th edition of 2013. In the 5th edition, there is a graph in its place that connects “cloudlets” with each other in the form of concentric circles. ↩︎
- Several elements can be found in the recent article by Dwayne Wisneck, The geopolitical economy of the global internet infrastructure, Journal of Information Policy, 2017. ↩︎
- See “Access controlled: the shaping of power, rights, and rule in cyberspace”, Deibert, Palfrey, Rohozinski, Zittrain (ed.), MIT Press, 2010. On the other hand, the Chinese state may not currently need more sophisticated methods. ↩︎
- Not to mention the achievements of Greek parties with armies of trolls…. These became known for SYRIZA of course (at the forefront of digital governance!), but it is more than certain that corresponding tactics are deployed (or will be deployed) by the rest of the party establishment as well. ↩︎