
The latest step in the discussions that began in July 2023 regarding the deregulation of genetically modified organisms (GMOs) in Europe took place on January 28, 2026, when the relevant proposal was voted in favor of in the “Environment, Public Health and Food Safety Committee” (ENVI) of the European Parliament. This vote followed the approval of the proposal by the EU Council on December 16, 2025, and the process still has several steps to go within the complex bureaucracy of the EU until final approval and legislation of the proposal, which only causes headaches for anyone trying to follow and understand it.
According to the relevant proposal, genetically modified organisms (GMOs) derived from the so-called “new genetic technologies” (NGTs—see CrispR-Cas9, mRNA platforms, etc.) should not be prohibited based on current European GMO legislation, as companies and their scientists argue that these new techniques are safer, more precise, and more effective… Thus, it is proposed that these “new GMOs” be divided into two categories: NGT-1, which should be fully deregulated, and NGT-2, which will continue to be restricted. The criterion for this distinction is the arbitrary number of 20 mutations, meaning that any organism/product carrying up to 20 NGT-induced mutations will belong to the first category… And according to current estimates, 90% of NGT-organisms could fall into this category.
The issues discussed in these talks include a) “sustainability and monitoring”, that is, safety b) “traceability and labeling”, that is, the obligation of relevant labeling on products and their location at every stage of the transport and processing chain, and c) “patents”, that is, what everyone can understand… Or maybe not;
The concept of a patent, as most of us understand it, involves applying “exclusivity” to a respective “invention,” which must meet certain conditions: a) it must provide a solution to a specific problem—the technical character of the invention; b) it must be novel, meaning not known based on the current bibliographic/technological state; and c) it must be “non-obvious,” meaning it must “involve inventive activity and not be obvious to the average specialized scientist or technician in the relevant field.” Additionally, the validity of each patent has an expiration date, upon which the application must be reassessed.
In the case of GMOs, the situation is a bit different… Initially, the relevant proposal wants patents on GMO-1 not to expire – with whatever that might entail. But what is even more “hidden,” amidst the technical terminology and legal acrobatics, is that the relevant patents will not only cover the specific products that will be manufactured via GMOs, but also anything in nature that happens to have the patented gene. “Nice,” one might say, “we already knew this from the accidentally contaminated GMO crops, where substances containing a ‘patented gene’ would spread to other fields, and thus the company would claim compensation from the farmers.” However, here the reality is more advanced and is already happening. For example, in December 2025, patents were approved for specific – resistant to “something” – varieties of tomato, lettuce, and spinach, which cover any variety in the world found to have the patented genes. But how is this possible?
Here, “new technologies” come into discussion – broadly speaking. From the digitization and registration in databases of genetic sequences, modern techniques for extracting genetic samples, up to computer factories (datacenters) and neural algorithms. Always together with the relevant legal acrobatics and the “negotiations” by powerful lobbies for establishing favorable legislation, the resulting picture includes the following: recognition of the trait of interest, recording the genetic sequence of the organism carrying it using modern “pocket-sized” tools, sending the sample to databases, reproduction/ printing of the gene of interest via NBT, and patenting the NBT-constructed gene. In this way, companies claim EVEN the natural organism found in nature, since local farmers cannot prove that their varieties had this gene prior to the issuance of the patent!
It might seem excessive, but essentially we are talking about patents on nature itself. Because the issue is enormous, here we translate a collection of texts1 that focus on DSI, which are among the fundamental parameters for this “image” to be formed, and more specifically on biopiracy. As a whole, this “image” includes much more than the injustice in the distribution of benefits to the local communities where the respective plants/organisms etc. exist, as the political economy of natural appropriation is not limited only to profits that are not shared equally. Relevant texts can be found in previous issues, in notebooks on workers’ use, and certainly in future reports.
Wintermute

Introduction to DSI
A semantic UFO, initially appearing as a new scientific concept, has recently dominated all discussions concerning seeds, biodiversity, and intellectual property. Some call it DSI (Digital Sequence Information), while others refer to it as GSD (Genetic Sequence Data). It is a “flying object” because it circulates freely in cyberspace in the form of electronic computer signals displaying them as a succession of four letters (A, C, G, T or U: ACGT for DNA, ACGU for RNA). “Of unknown identity” because the more it is discussed in international political forums (ITPGRFA, CBD, etc.), the less it is possible to define it.
The absence of an internationally recognized definition results in countries of the global South, the main suppliers of genetic resources, interpreting DSIs as the genetic component of natural organisms, while countries of the global North, the main users of these resources, interpret them as research products. But this does not prevent patents on genetic information from extending also to the natural organisms that contain them. The absence of a definition of this information currently hinders discussions regarding the legal framework for new genetic modification techniques (NGT), being the elephant in the room that no one dares to mention.
These words refer to the same “object”. But while DSIs are immaterial data, a component of a physical organism, even the genetic component, is material. As for genetic information, it is by definition immaterial like all information, but it also has a material form because it is contained in biological matter (DNA). What are the consequences then of playing with words?
For the international law dictated by the industrial “Global North,” life and knowledge are primarily industrial resources. The Convention on Biological Diversity (CBD) is a treaty between states that sets the rules for accessing biological resources and related knowledge essential for industrial development. Any access requires the signing of a bilateral agreement based on the prior consent of the state from which the coveted resource originates. This state may delegate this consent to the individual, the indigenous population, or the local community that manages the resource and holds the related knowledge. This consent may be linked to terms of use (which may be the subject of research or also be reproduced, commercialized, transformed, genetically modified, patented, etc.) and to the distribution of benefits arising from their exploitation. Since the adoption of the CBD in 1992, these terms have generally been circumvented, as most biological resources are freely available in many public collections, with no connection to their origin. This also applies to their description, in numerous freely accessible publications, of their chemical and genetic components, which can be copied without any direct use of the original biological resource. The distribution of benefits is therefore limited to a few dollars, which fund the work of NGOs, researchers, and sometimes organizations of indigenous populations responsible for collecting and providing biological resources not yet available, as well as the related knowledge held by farmers and people who make a living from these resources and maintain them.
The International Treaty on Plant Genetic Resources for Food and Agriculture (ITPGRFA) concerns the application of the CBD to seeds. It replaces bilateral prior informed consent with a multilateral access system (MLS), mainly in large national and international gene banks. This access is not free, but “facilitated,” as it depends on the obligation to share benefits and the prohibition of claiming any intellectual property rights that restrict access by other entities to the provided resource, as well as to its parts or genetic components. A Benefit-sharing Fund is funded mainly by a few countries, with much lower amounts than those promised, as the seed industry exploits the lack of effective traceability of seed exchanges to pay only small amounts. This fund also finances institutions, NGOs and researchers responsible for supporting farmers to save their seeds, collect them for the multilateral system and publish relevant knowledge.
The fact that genetic sequences of millions of biological resources and thousands of publications related to associated traits are now freely available on the Internet, undermines both the prior consent of the CBD and the access conditions within the framework of the ITPGRFA. “Artificial intelligence” algorithms use millions of this data to create predictive models of genetic engineering, creating organisms, components and products of synthetic biology… patented even before they exist.
Thousands of patents have been granted for genetic information incorporated in this way into plants, animals, microorganisms, fungi, pharmaceutical, veterinary and biological products or/and for the “new genomic techniques” (NGTs) used to obtain these products, although only a small number of them have actually been developed and brought to market. Since they are no longer directly linked to access to natural biological resources but only to intangible data (DSI) considered research products, all these patents circumvent the sharing of benefits. The CBD is therefore examining the appropriateness of a financial contribution upon the commercialization of any product resulting from the use of DSI, which would be paid into a common fund. For its part, the ITPGRFA has been discussing the same issue for 10 years. But disagreements within the sector, supported by countries of the “global North”, prevent any decision, while more and more patents are being granted.
Since 1998, the European directive 98/44 on biotechnology provides that “the protection conferred by a patent on a product containing or consisting of genetic information extends to all material into which the product is incorporated and in which the genetic information is contained and performs its function.” However, the patenting of nature and natural selection processes, known as “essentially biological,” is prohibited. The transgenic techniques capable of integrating such genetic mutations into biological organisms leave easily recognizable signatures (promoter, terminator, etc.). Therefore, with these techniques, the scope of patent protection should be limited exclusively to the products resulting from the “invention” and to products contaminated by patented genes.
However, no! The new fairy tale of industry and the governments of the richest countries is that “new genetic technologies” (NGT) make it possible to “produce” genetic information that cannot be distinguished from that contained in natural organisms or derived from traditional, non-patentable techniques. In reality, the encoded description of patented genetic information itself may indeed not be “discernible,” but never the entire modified organism. This happens because NGT systematically produces many additional, so-called “unintended,” genetic modifications that constitute undeniable “signatures” of the use of genetic engineering technology on which the patent is based.
Nevertheless, the scope of the patent extends to any material containing the patented genetic information. Therefore, it also extends to all organisms that naturally contain it or as a result of using traditional, non-patentable techniques. For this reason, pharmaceutical, agrochemical, seed and food companies believe they can appropriate and control all biological diversity under the sun… But more and more farmers and citizens are mobilizing to abolish this new form of biopiracy.
DNA Sequencing and the Earth BioGenome Project
The sequencing and recording in electronic databases of the genome of living organisms that constitute biological diversity is one of the cornerstones of the ongoing appropriation of living organisms. This information, known as “digital sequence information” (DSI), is the subject of international negotiations within the framework of the Convention on Biological Diversity (CBD), the International Treaty on Plant Genetic Resources for Food and Agriculture (ITPGRFA), and the World Intellectual Property Organization (WIPO). The goal of these negotiations is to determine the legal regime and conditions required to protect biodiversity from biopiracy. The Earth BioGenome Project, which has been underway since 2008, is not a science fiction scenario, but demonstrates the enormous stakes involved in these DSI.
In 2019, we presented in our article the Earth Biogenome Project, an international project that had started the previous year. Whether it was simply an announcement or not, the project seemed excessive from the outset, as its goal was to sequence the genomes of 1.84 million known eukaryotic species (organisms with cells that have a nucleus), out of an estimated 12 to 15 million. In 2008, it was announced that the project would take 10 years to complete, with an estimated cost of 4.7 billion dollars. By now, the project has far exceeded its theoretical timeline, and the goal of sequencing millions of genomes still seems very, very far away. According to the project’s website, the genomes of only 3,039 species have been sequenced.2
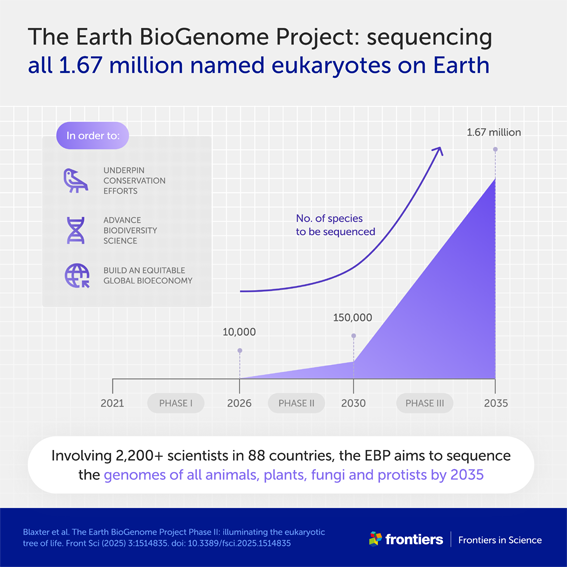
The Earth Biogenome Project is an umbrella project that covers many other projects. There are 64 of these, which may differ from each other based on geography or the organisms that have been sequenced. The list of projects published online includes one named “1,000 Chilean Genomes,” which aims to “decrypt the genomes of animals, plants and microorganisms endemic to Chile.” The “African Biogenome Project” covers the entire African continent, with the goal of building “capacity (and infrastructure) for creating, analyzing and developing genomic data to improve and sustainably use biodiversity and agriculture throughout Africa.” The European Union is of course present with the “European Reference Genome Atlas,” which is “a pan-European community initiative to coordinate the creation of reference genomes representing European eukaryotic biodiversity.”
Some projects also target types of organisms rather than geographic regions. The “Ocean Genomes” project aims to “accelerate and expand the production of openly accessible genome collections for marine vertebrates” found in all oceans. The depths of the ocean have not been forgotten, as the “Deep Water Genomes” project will explore and collect samples for sequencing, while the “Polar Genomes” project aims to “encourage research on the unique characteristics and functions of genomes that enable distinctive and powerful biological processes in polar organisms.” Mammals, fish, birds, insects, crabs, butterflies, ants, amphibians, bees, bats… are now at the center of numerous similar projects.
The “Wise Ancestors” project is somewhat unique among these. Its mission, as stated on its website, is to co-create and develop “research projects focused on species conservation challenges, in collaboration with indigenous peoples and local communities, aiming to produce genomic information, enhance local conservation efforts, and support indigenous data sovereignty.” Put simply, this project coordinates the work of researchers and local communities to sequence the genome of species that are known to and used by these local communities, as well as to collect the relevant traditional knowledge.
Apart from being a tangible example of the risks of biodiversity appropriation through the use of DSI and the collection of related traditional knowledge, this project is particularly innovative regarding its funding. Its website states that its only funding source is the Future of Life Institute. In the European Union, this foundation is registered in the Transparency Register due to its meetings with members of the European Commission and the European Parliament, between 2021 and 2024, regarding legislation on artificial intelligence, which was approved last July. As the foundation itself states, its financial resources come from donations it received and subsequently redistributed in the form of grants. Donors include Vitalik Buterin, co-founder of the cryptocurrency Ethereum, Jaan Tallinn, founder of Skype, and, in 2015, Elon Musk, co-founder of Space X, Tesla, PayPal and OpenAIx. If we look at it from the reverse perspective, the path described here shows that it is the key players in artificial intelligence and cryptocurrencies who are investing in genome sequencing and mobilizing researchers and local communities.
Why then, does the Earth BioGenome Project concern us? One of the issues is intellectual property. Sequencing genomes feeds databases that store DNA sequences (DSI). DSI themselves constitute a source of information that can be used to develop an “invention” and claim a related patent. In the field of life, patents have the peculiarity that they must include the information constituting the invention in question, along with any organism containing this information. The recent case of a patent by KWS company for corn plants resistant to cold, which was unsuccessfully challenged before the European Patent Office (EPO) and threatens the work of farmers who had selected cold-resistant corn varieties prior to the patent application, proves this. This is also demonstrated by the recent adoption within the World Intellectual Property Organization (WIPO) of an international treaty for which every possible effort has been made to ensure that the origin of the “material” (in our case, natural organisms or DSI) does not need to be mentioned, thus making it easier to extend the scope of a patent far beyond the unique “invention” claimed.
In the case of the Earth BioGenome Project, there are recommendations to ensure that all sampling will be conducted in accordance with international rules. The general approach is that “sample collectors should ensure that all local and national permits for collection are in place and that there is a record of these permits that can be referred to if questions arise regarding whether a sample was legally acquired.” However, the conditional clause used in this approach, as well as in the other recommendations for sample collection, raises concerns, as compliance with national or international rules is rarely enforced, while it only partially covers the established procedure for collection and transfer under the Nagoya Protocol: while it includes obtaining consent and a benefit-sharing agreement, it overlooks the fundamental agreement regarding the transfer of material. This omission can be explained by the fact that this “best practice guide” is based on the idea that the work can be simplified with “artificial intelligence” tools. In reality, there are detailed reports that the Earth BioGenome Project promotes the simplification of standard procedures to facilitate extraction, sequencing, and synthesis activities. This “ease” means that a simple portable laboratory could be sufficient to sequence the sample. This reduces pressure on the requirements of the Nagoya Protocol, as well as the budget for transporting and maintaining a transport “cold chain” (regarding temperature for sample transportation).
This approach is based on the absence of a legal definition and regime for DSI, while at the same time many negotiations are underway at the international level and certain actors, especially in Europe and North America, are pressing for DSI not to be subject to the rules governing the exploitation of biodiversity. While it is necessary to reach an agreement on the transfer of material, in order for an organism to be exported from the country where it is located, several countries believe that this should not apply to DSI. From this perspective, the Earth BioGenome Project raises the issue of biopiracy in an even more intense way, and even more so given that any such access to genetic information is already irreversible, since there are many accessible DSI databases, both in public collections of genetic resources that do not document the origin of natural organisms, and in many private ones.
Genome digitization through “artificial intelligence”
The use of computer algorithms operating in real factories to exploit ever-increasing amounts of information is one of the themes of 2025. These computer factories, mistakenly called “artificial intelligence,” require ever-larger computer servers, which in turn consume ever-increasing water and energy resources. But above all, their use in the digitization of living organisms deserves a closer look for those following the GMO issue. At a time when multinational corporations are intensifying their efforts to domesticate living organisms, in what way do these algorithms become tools of monopoly?
Since 2008, the Earth BioGenome Project aims to sequence the genomes of millions of species at a cost of at least five billion dollars, and while by December 2024 only 3,039 genomes had been sequenced, the ambition remains and the expected amount of data is staggering. In a report published in January 2025, the organization Save our seeds provides several revealing figures. The sequences of 13.8 million proteins from 342 different plant species are stored in a database created by university researchers called PlantMWpIDB. Another public database, PlantExp, contains the sequences of 131,400 transcriptomes, that is, all the RNA molecules identified in a genome. Another database, Pmhub, contains descriptions of 188,837 plant metabolites. These data are given as examples. It is impossible to have an idea of the total amount of information produced and stored. The ABS Biotrade project notes that sequencing genetic information has become such a common practice in all fields of biological sciences that it leads to the creation and storage of a huge amount of information every day.
From a technical point of view, the production of these data became possible thanks to the lower cost and increasing speed of sequencing methods. As Save our Seeds reports in detail in its report, the first sequencing of a complete genome, that of Arabidopsis Thaliana, published in 2000, required 10 years of work at a cost of 100 million dollars. Whereas, 25 years later, in 2025, sequencing the genome of a plant takes only one week, at a cost of less than 1,000 dollars. Besides these sequencing methods, there are also the so-called “omic” methods, which study all the types of molecules present in a cell: proteins and RNA are two examples. The goal of many companies today is to create a map of the molecules produced and present in a cell, a kind of “Google Maps of plants,” as Save our Seeds calls it. In 2021, a conference on the first atlas of plant cells brought together 500 representatives from governments, research institutes, and companies such as Bayer, Google, and Syngenta.
To process this growing volume of data and perform the required tasks, algorithms need hardware, energy, and water. The numbers here take on a dimension that is difficult to comprehend. At Elon Musk’s company, for example, xAI, which claims to accelerate scientific discovery, the Colossus data center, based in Memphis, USA, has demands that are rarely met. These servers operate with 100,000 processors provided by Nvidia. These processors require the equivalent of 150 megawatts per hour to run, which corresponds to the needs of 100,000 households for the same duration. To obtain this amount of energy, the xAI server is currently powered by turbines fueled by methane. For the coming years, players in this sector are working on mini individual energy production stations. In France, EDF has launched a subsidiary, Nuward, to design and build such reactors in 2023.
Energy, however, is not the only problem. These servers, like all data centers, must be continuously cooled. To achieve this, the water requirements are also impressive. Looking again at the xAI data center, it requires over 3.5 million liters of water per day. In relation to the population of France, for example, this corresponds to the average daily consumption of over 22,300 households… And in the fall of 2024, xAI announced plans to double the size of the data center.
At the same time, the volume of sequencing data is expected to increase exponentially. The Earth BioGenome Project mobilizes more than 60 projects globally, on land and at sea, to collect samples from most, if not all, organisms, with this data subsequently stored electronically in data centers. Several cases demonstrate that private algorithms are increasingly being used to be fed by this digital data, primarily to design genetic modifications that laboratory researchers in multinational companies would like to implement. For several years now, IT companies have been mobilizing at the crossroads of algorithms and biotechnologies. A report published in September 2024 by the African Centre for Biodiversity, the ETC Group, and the Third World Network, for example, details that Google, Microsoft, Amazon, and Nvidia have invested in and developed projects related to living organisms. For instance, Google has established a company, together with Ginkgo Bioworks, to create new proteins using Google DeepMind’s “artificial intelligence” algorithms. Meanwhile, Amazon’s founder, Jeff Bezos, has invested $100 million through the Bezos Earth Fund to create new proteins using his own algorithms.
Thus, in recent years, the development of computational capability for executing these algorithms has been at the center of an increasing search for funding. As a more recent example, on February 11, 2025, the European Union launched an initiative to raise 200 billion euros for investments in this sector. According to JP Morgan, over 1.000 billion dollars could be invested between 2024 and 2027, while simultaneously, at the intersection of computer science and biotechnology, the value of the biotech market was estimated, in 2023, at 1.500 billion dollars, with related sectors ranging from molecules used in medicine to genetically modified plants used in agriculture, agrochemicals, biofuels, etc.
At a time when the European Commission is proposing the deregulation of many GMOs from 2023, the emergence of this (erroneously) so-called “artificial intelligence” technology appears to constitute a complete shift from the existing technical paradigm, as the landscape of multinationals involved in the agri-food chain could be restructured in the coming years. As for citizens, their position in this technological development is, for now, that of mere spectators, when they are not themselves providers of personal data.
The connection of DSI with “new biotechnologies”
All new biotechnologies are essentially “modern biotechnologies” as defined in the Cartagena Protocol. The CBD classifies them as “synthetic biology.” The European Commission uses the term “new genomic techniques” (NGT) or, for plants, “new breeding techniques.” The multiplication of new names without internationally recognized definitions aims exclusively at creating confusion, in order to exclude these techniques from the scope of the Cartagena Protocol, which would then apply only to transgenic techniques. The same confusion from multiplying new names applies to so-called “bio-enriched” seeds. There are some rare traditional bio-enriched seeds, but the overwhelming majority are simply genetically modified.
The industry also wants to exclude from this scope of application other products derived from these modern biotechnologies, such as RNAi pesticides, vaccines, viruses… because – they say – they are not themselves living organisms, even though they are disseminated with the aim of modifying the genome or epigenome of living organisms. To date, the CBD has not completed its discussions on the subject.
– What are genetic information;
The gene is not an organism, but it is an essential structural element of living organisms. It consists of nucleic acids, which are tangible chemical molecules. The gene is therefore a physical, tangible substance. Some genes are considered to carry information that determines a specific biological characteristic of the organisms that contain them. Today, we know that the same biological characteristic often depends on many genes and that, in different contexts, the same gene can create different characteristics or no characteristics at all. But international law does not deal with these details…
Information, on the other hand, is not a material substance. However, genetic information is defined only by its material support, the genetic sequence. Geneticists refer to “the gene that encodes a protein,” while lawyers speak of “the function of the gene.” However, this material support can be digitized into computer data, which can travel across the planet and appear on screens in the form of an ordered succession of the 4 letters (A, C, T, G or U). But these letters by themselves say nothing about the function of the genetic sequence they represent. This function must be determined elsewhere.
– Genetic information, the Cartagena Protocol and patents
The first patents for genes were granted in the US in the 1980s, after many disputes regarding the privatization of living organisms. In 1998, the European Union adopted Directive 98/44/EC on biotechnology, according to which (Article 9) “the protection provided by a patent on a product containing or consisting of genetic information extends to all material into which the product is incorporated and in which the genetic information is contained and performs its function.” Therefore, for the European legislator, genetic information is contained in a product or constitutes the product itself and can provide exclusive rights to use the materials that contain them. Although intangible, they remain an inseparable part of these biological materials.
Also, the European directive does not clarify whether this exclusive right of use is limited exclusively to biological materials derived from the specific technical process that justifies the patented invention. It could therefore extend to products derived from traditional techniques and which naturally contain these genetic informations, which are similar in their description to those claimed by the patent and express their function. Until today, only the Cartagena Protocol has limited the risk of abusive extension of the scope of patents to “inherent characteristics”. In Annex II of the protocol, the existence of “any unique identification” of the “Living Modified Organisms” (LMOs) intended for food, feed or other processing is required, as such identification makes it possible to distinguish the patented LMO from any other product. Consequently, the scope of the patent for an LMO can be extended only to this LMO and to products derived from or contaminated by this LMO, and not to the inherent genes of traditional products. Of course, the wealthy countries hosting the largest industrial companies want to remove this obstacle to biopiracy and for this purpose, they develop a series of fantastic stories claiming that the new biotechnologies are not modern biotechnologies in the sense of the Cartagena Protocol.
While internationally adopted regulatory protocols exist for detecting and identifying genetically modified organisms (GMOs), the same cannot be said for GMOs produced through “new biotechnologies.” All patent holders possess the process that allows them to detect and pursue anyone who infringes their invention, and these processes could be included in the identification protocol obligations. However, according to patent law, they constitute confidential information protected by industrial secrecy. This confidentiality allows the European Commission to claim that there is no way to distinguish between GMOs derived from new biotechnologies and organisms originating from traditional techniques, and consequently, to propose their exclusion from the Protocol’s scope of application. While the DSI of a single modified gene may not suffice to substantiate this distinction, the same cannot be said for describing the entire modified organism, including the genetic, epigenetic, molecular, and other signatures of unintended on-target or off-target effects of the genetic techniques used, which enable the unique and unequivocal identification of the organism. This is also why industry and the European Commission want to limit regulation only to the genetic characteristic (DSI) claimed in the patent, without taking into account the entire genetically modified organism.
Moreover, a patent holder can seize competitors’ products based exclusively on alleged infringement. It then falls to the accused party to prove that their products do not originate from the patented invention. This can only be done if they have previously published in an official document, before the first claim of the patent, that their product already contained the genetic information referred to in the patent, while simultaneously having deposited a sample in an official collection that allows them to prove it. Farmers and small local seed companies do not sequence or deposit in official collections the millions of new seeds they select and store each year. If these seeds naturally contain genetic information described as similar to that protected by a patent, only the obligation to publish the unique identifier of the GMO can allow them to prove they have not copied the patented invention. Excluding new GMOs from the scope of the Cartagena Protocol would remove this obligation and, consequently, legitimize biopiracy, blatantly violating the rights of farmers and indigenous populations enshrined in the ITPGRFA and the United Nations Declaration on the Rights of Farmers (UNDROP).
In July 2014, the ITPGRFA held a ceremony dedicated to the 10th anniversary of its entry into force. On this occasion, its Secretary, Shakeel Butt, announced the signing of the Treaty’s commitment for the new program, DivSeek, which has been designed to publish online in open access the genetic sequences of the two million seed samples stored in genetic banks available through the Treaty’s Multilateral System of Access and Benefit-sharing (MLS).
The complete sequencing of the first plant, rice, which began in 1993 in Japan, was completed just 12 years later, in 2005, one year after the signing of the Treaty. It mobilized hundreds of researchers from 11 different countries and millions of dollars. In 2014, sequencing a plant sample already required only a few days and a few dozen dollars. Today, it is fully automated, takes only one or two days, depending on the required accuracy, and costs only a few dollars.
This observation allowed the La Via Campesina representative to respond to Shackel Batthi, who was expecting compliments, denouncing his initiative: “With the advancement of techniques, the connection of genetic and phenotypic data of plant genetic resources facilitates the filing of patent applications for plant characteristics, including the so-called “native” characteristics that already exist in nature. Such patents allow the appropriation of these resources and herald the death of the facilitated access that supports the MLS. They also herald the end of farmers’ rights, who can no longer use or exchange their own seeds when a patent is registered on a gene that already exists in nature or when they have been contaminated by patented genes.”
Access to plant genetic resources for food and agriculture (PGRFA) based on the MLS is “facilitated,” which means it is exempt from any bilateral agreement between provider and recipient. However, it is not free, as it still involves the obligation to share benefits and prohibits patent claims on the provided resource, its parts, or its genetic components. Therefore, DivSeek’s free access to the genetic sequences of these resources constitutes a violation of the Treaty. Shackel Batthi made a serious mistake by committing the Treaty to the DivSeek program, and moreover, without seeking the agreement of the Governing Council’s Administration. He lost his position two years later and immediately returned to his previous employer, the World Intellectual Property Organization (WIPO), which he had, in fact, never actually ceased to serve.
In 2017, the new concept of DSI appeared in the daily arrangement of the Treaty. The lack of traceability of the origin of a patented DSI allows industry to claim that it has not used any PGRFA from the MLS. This exempts industry from the obligation to share benefits, from the prohibition on patenting the genetic components of PGRFA, as well as from extending the scope of application of the patents in question to natural or traditionally cultivated seeds containing the same DSI. This has caused intense discussions between, on the one hand, countries of the Global South and farmers who are the main suppliers of PGRFA and who consider DSI to be genetic resources subject to the obligations of the Treaty, and, on the other hand, rich countries of the Global North, which consider DSI to be research products not subject to these obligations.
A genetic sequence by itself cannot be patented unless it is the result of an invention that can be patented, such as new biotechnologies, and without indicating its function, which is the phenotypic trait resulting from its expression. Thus, with the derecognition (i.e., lack of identification process) of PGRFA, the benefit-sharing process becomes the main tool for determining these functions. Opening access to PGRFA resources eliminates any possibility of bilateral agreement between farmers who supplied their seeds and the rights holder, and this is why the Treaty has created a multilateral Benefit-Sharing Fund, which is funded almost exclusively by a handful of countries, with amounts far lower than what the industry should contribute, which refuses to fulfill its obligations. This fund does not compensate farmers who supplied their PGRFA to the MLS, but rather the national seed banks of developing countries, which fund researchers and NGOs that collect new PGRFA, selected by farmers—as well as their associated knowledge related to these PGRFA. Access to funding from the Benefit-Sharing Fund requires these national seed banks, researchers, and NGOs to deposit PGRFA into MLS collections and to publish the relevant knowledge associated with the functions of the genetic sequences they contain.
DivSeek and similar programs now offer free access to several billion genetic, epigenetic, and protein sequence resources of PGRFA. Scientific publications, NGO reports, and those from the Treaty’s information system allow the creation of databases with the characteristics of each PGRFA. Powerful computer search engines of some major companies in the sector are now capable of processing millions of data points to determine which genetic sequence in a PGRFA sample “codes” for which function. Thus, all they have to do is have their geneticists write a story about how they can introduce this genetic information into laboratory varieties through a new patentable biotechnology, and then encourage their lawyers to translate this geneticists’ story into the legal language of a patent application for plants containing this genetic information. Subsequently, they can announce new promises for solving all real agricultural and nutritional problems, while simultaneously prohibiting their competitors from using the patented biotechnology and genetic information or requiring them to pay significant licensing fees.
Only after this first step do they attempt to introduce the genetic information into their commercial varieties in reality. But this second stage rarely succeeds, because the real living world does not operate according to the laws of the intangible “artificial intelligence.” It does not comply with the probability calculations of computational modeling, which constructed the patented genetic information and subsequently designed the technical process for introducing them into real plants. Only a handful of random successes have made it possible to develop new seeds from these new biotechnologies that have entered the market. This difficulty in transitioning from the virtual world of “artificial intelligence” to the real living world is the cause of the gap between the thousands of patents and publications on new GMOs and the few plants already on the market. However, this does not prevent these patents from fueling the exponential acceleration of the concentration of the seed industry in the hands of the four or five major seed companies in the world, which hold the largest portfolios. Most of these large seed companies are also chemical and pharmaceutical, which also invest in new “biological control” plant medicines, drugs, veterinary products, microorganisms and robotic animals… which come from the same new biotechnologies.
Are there solutions?
Due to lack of funding for the Benefit-sharing Fund, the Treaty established a working group in 2013 to improve its operation. After systematic obstacles from the sector and the few wealthy countries that support it, it suspended it in 2019, pending a possible solution that would be proposed by the CBD.
To date, the CBD has not yet reached an agreement regarding the definition of DSIs. Instead, it has introduced the new, also vague concept of “Genetic Sequence Data” (GSD). However, it has raised the possibility of replacing the bilateral benefit-sharing with a multilateral fund financed by contributions from any commercialization of products derived from the use of DSI biological resources. However, it has not explained how such use would be determined. Industry will still be able to circumvent payment obligations by claiming patents, not on the genetic information of biological resources (DSI/GSD), but on the biological materials themselves obtained through chemical or genetic synthesis, as has long been the case with corresponding chemically synthesized copies of natural substances, many of which are patented drugs.
At the beginning of 2023, the ITPGRFA re-established its working group for the operation of the MLS. The CBD proposal favors the imposition of a flat fee on all seed sales by companies using the MLS, but without excluding the optional recourse to the current completely ineffective case-by-case payment system for trading products that result solely from the use of the MLS. This mechanism would exempt large companies that use only their own collections or/and other public collections that remain open, such as those in the USA. Moreover, in contrast to the CBD, which is limited only to the obligation of benefit-sharing, the ITPGRFA also prohibits any patenting of the genetic resources of the MLS. If the CBD solution, which does not take this prohibition into account, is ever finalized, it will not be sufficient by itself to comply with the Treaty (ITPGRFA).
Wouldn’t it be simpler to admit that the massive investments in new biotechnologies are exclusively aimed at the profits that will be gained from patents and offer no solution to the real challenges concerning food, society, climate, health and the environment… which, on the contrary, they are likely to worsen? Wouldn’t it be a solution to ban all patents on living organisms?
Translation / Adaptation: Wintermute

- The material has been drawn from work by red scarves on the relevant issue. ↩︎
- Note: The number in the text we are translating is from December 2024. Now, February 2026, the project’s website states that this number has reached 5,206 organizations. ↩︎